
For all the news organizations that have adopted automated journalism over the last decade or so, the COVID-19 pandemic could have been the perfect story to automate as the technology draws on structured data that can fit into predictable story frames. This report documents the experiences of nine media organizations that have done so and gives an overview of the ad hoc solutions journalists used to work around the challenges of having to rely on external datasets. It shows the importance for media practitioners to be able to solve problems through applying computing skills, a form of knowledge known as computational thinking or computational journalism in a newsroom setting. This type of mindset has given journalists a considerable edge in deploying automated news quickly and efficiently in the midst of a global pandemic, but may also fuel ideas for the next iteration of these products.
Key findings:
- Seven of the nine news organizations featured in this study already used automated news for other types of coverage, while two experimented with it for the first time.
- For the most part, these organizations developed their automated news systems in-house, using open-source and proprietary solutions, except in two cases where they used third-party platforms so that journalists could design their own automated stories. In one case, the production of automated news was outsourced to an external content provider.
- All nine media organizations used automated news on COVID-19 either to provide a statistical overview of the spread of the virus through user-facing interfaces and new media products, or to deploy new forms of newsroom workflows that involved contributing to the creation of automated news or working directly with them.
- The challenges that newsrooms faced when using automated news to cover COVID-19 demonstrate the difficulties associated with having to rely on external datasets. These included:
- Getting data from several levels of government;
- Receiving erroneous data and sudden changes of format;
- Releasing data too soon or too late.
- To remedy these challenges, some interviewees had to develop ad hoc solutions, such as:
- Using a shared spreadsheet to work across teams;
- Setting up an alert system to work with tight deadlines and sudden changes of format;
- Keeping historical records to make calculations and to be better accountable.
- The process of developing these ad hoc solutions highlights the value of computational thinking and skills to media practitioners. This type of mindset has given journalists a considerable edge in deploying automated news quickly and efficiently in the midst of a global pandemic, but may also fuel ideas for the next iteration of these products.
In a sense, COVID-19 could be the perfect story to automate. When the virus spread globally at the beginning of 2020, governments and health authorities made accessible a considerable amount of open-source data, generally available through structured datasets or APIs (application programming interfaces). These statistics contained critical information such as the number of deaths and patients in intensive care units as well as 7-day incidence rates. This type of structured data that can fit into predictable story frames lays the groundwork for automated journalism, a computational process that creates automated pieces of news without any human intervention, except for the initial programming.
Automated journalism usually implies the use of algorithms that fetch information from external or internal datasets, and then fill in the blanks left on templates that have been written in advance. This process, which can be compared to the word game Mad Libs, constitutes a basic application of natural-language generation (NLG), a computational technique that has been around for several decades in domains such as weather forecasts, sports, or financial results. Although there are fewer machine-learning approaches to automated news, this is a growing area of interest. For instance, some advanced machine-learning applications of NLG production are being advertised on the websites of companies that specialize in delivering automated content to business, media, and governmental organizations. The EU-funded project EMBEDDIA is also looking at incorporating elements of machine learning in automated news generated using pre-written templates, so as to make them less formulaic and more enjoyable to read.
NLG made a leap into journalism and started to be more widely discussed in the first half of of the 2010s as The Los Angeles Times used automated text to report on homicides and earthquake alerts, while The Associated Press partnered with the firm Automated Insights to automate stories on corporate earning. Numerous media organizations have subsequently adopted or experimented with automated journalism, including global news agencies like EFE and AFP, major newspapers like Le Monde and The Washington Post, and public service broadcasters like the BBC and YLE in Finland. Proponents of automated journalism typically develop their technology in-house, outsource it to an external content provider such as Syllabs in France and Narrativa in Spain and in the United States, or use third-party solutions so that journalists can design their own automated news, as it is made possible through Automated Insights’ Wordsmith and Arria NLG Studio. Automated news can be published simultaneously at massive scale, for instance when Swiss media company Tamedia generated almost 40,000 stories to report on the results of a referendum, or used as first drafts to assist journalists with their own writing, as was reported to be the case at Forbes and at the Wall Street Journal.
The availability of structured data during the COVID-19 pandemic, some of which could fit into predictable or templated story frames, provided an opportunity for media organizations with the necessary resources to use automated news in their coverage. This report outlines use cases at nine outlets from eight countries (Chapter 2) before homing in on some of the main challenges they faced and the solutions they found (Chapter 3). For this purpose, I conducted nine in-depth semi-structured interviews with media practitioners and executives between July and December 2020. The following media organizations were selected for analysis:
- Bayerischer Rundfunk (Bavaria’s public service broadcaster, Germany);
- Bloomberg News (news agency, United States);
- Canadian Press (news agency, Canada);
- Helsingin Sanomat (newspaper, Finland);
- NTB (news agency, Norway);
- Omni (news service, Sweden);
- RADAR (news agency, United Kingdom);
- Tamedia (media group, Switzerland);
- The Times (newspaper, United Kingdom).
Of these nine media organizations that deployed automated news to cover the pandemic, seven were already using it for other types of coverage such as election results or sports recaps (BR, Bloomberg, CP, HS, NTB, RADAR, and Tamedia). Another two experimented with automated journalism for the first time (Omni and The Times). For the most part, these organizations developed their own automated news products using open-source tools and proprietary solutions, including an advanced machine learning system designed by Bloomberg’s engineers. In two cases (Tamedia and RADAR), they used a third-party platform so that journalists could design their own stories, and in one case (Omni) the production of automated news was outsourced to an external content provider. In the next section, I will describe how these organizations used automated news about COVID-19 to provide readers and media clients with user-facing interfaces rounding up the latest numbers on the virus, or to deploy new forms of newsroom workflows that involved either setting them up or working directly with them.
Two different ways of using automated news during COVID-19
a. Quantifying the pandemic for readers and media clients
The first use of automated news to cover the COVID-19 pandemic has to do with providing a statistical overview of the spread of the virus to media clients and audiences alike, either through user-facing interfaces such as dashboards and newsletters, or through an extended range of news products. For instance, Tamedia and The Times featured national and international dashboards that summarized the latest COVID-19 data with automated text along with a great many automated or semi-automated graphics, such as a table outlining the number of vaccination doses administered per 100 people across the world or a map showing weekly cases per 100,000 inhabitants of the United Kingdom. Whereas The Times has used automated graphics in the past, using automated text generation was a first: “It was really the first time where we felt the need for such a long-term investment in something that was automated,” explained a data and interactive journalist at the newspaper.
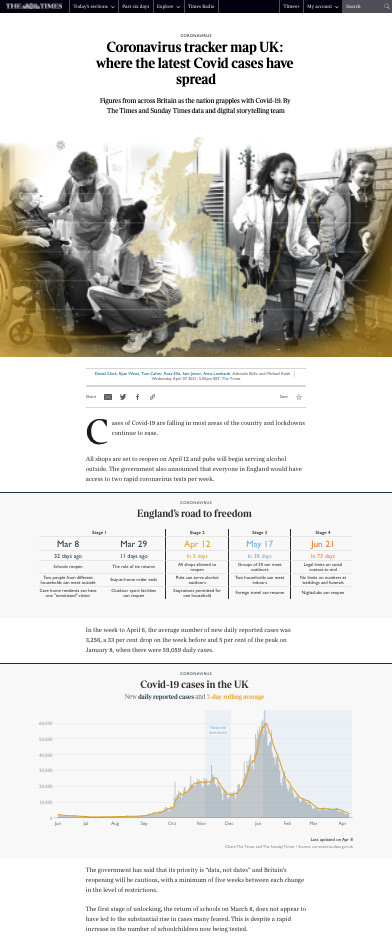
Above: Screenshot of the COVID-19 tracker page at The Times. It features automated text and graphics that give a breakdown of the latest coronavirus statistics in the United Kingdom. (Source: The Times)
This type of interactive dashboard also took the shape of a newsletter, such as the one launched at BR that contained automated text as well as tables, maps, and charts. This COVID-19 newsletter draws on raw data released by the Robert Koch Institute and is updated on a daily basis. It shows the spread of the virus in Bavaria and Germany and informs readers on a selected range of indicators such as total cases, deaths, and recoveries, as well as 7-day incidence rates at local levels. Similarly, automated stories generated daily at CP were used to feed an automated newsletter that would wrap up the most recent numbers for media clients. It included new data such as the number of confirmed cases, recoveries, and deaths, but also economic data drawn from other automated coverage at CP to account for the financial repercussions of the virus. Automated charts were also created to keep track of the number of new cases all across Canada.

Above: Screenshot of the automated COVID-19 newsletter set up by BR’s AI + Automation team on 19 February 2021. It informs readers on the spread of the pandemic in Bavaria and Germany. (Source: BR)
Another way of providing a statistical overview was through a new range of products that were available to media clients. For instance, the Norwegian news agency NTB delivered automated news on COVID-19 directly through its wire service, but also through an API that news organizations could use to set up their own interactive products such as live blogging platforms (smaller clients could also use NTB’s own platform for this purpose). These automated stories included health-related statistics such as the status of vaccinations across Norway, as well as unemployment and furlough figures caused by the pandemic. In addition, the news agency provided automated visualizations that were self-updating to give the latest roundup of COVID-19 numbers.
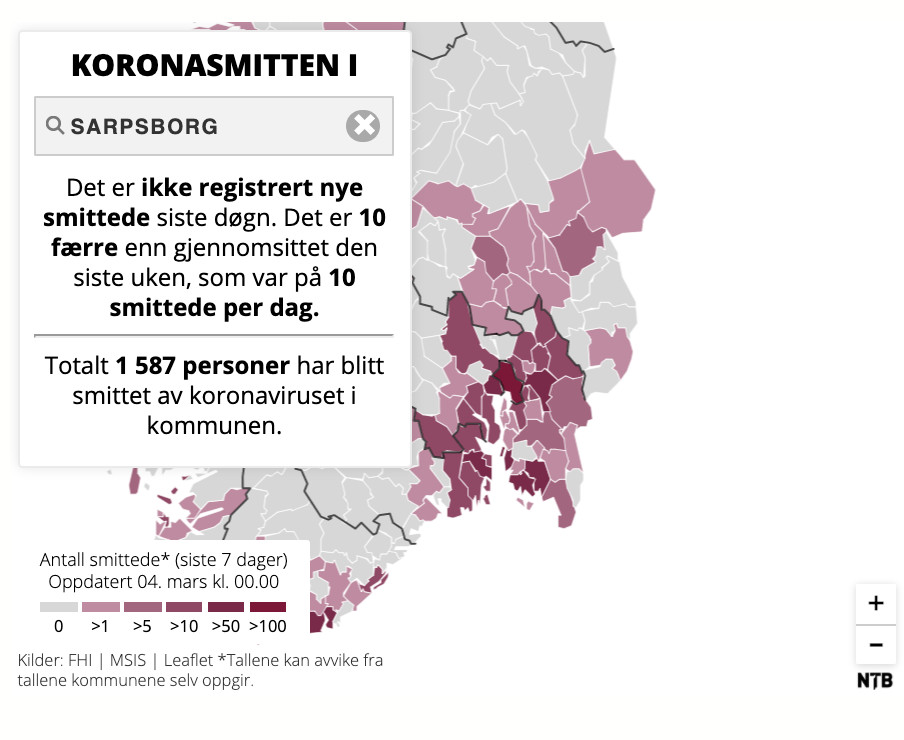 Above: An example of automated map and text on COVID-19 that NTB generated. NTB’s automated stories included health-related statistics, but also unemployment and furlough figures caused by the pandemic.
Above: An example of automated map and text on COVID-19 that NTB generated. NTB’s automated stories included health-related statistics, but also unemployment and furlough figures caused by the pandemic.

The need for these types of statistical summaries stemmed in part from a lack of clear data release strategy from government and health officials. According to a technical lead at BR’s AI + Automation Lab, health authorities were putting forward too many different indicators. He said that for a time, they were communicating only about absolute increases and total numbers, which made it difficult to track the evolution of the virus, before switching focus to more detailed figures such as doubling times, reproductive numbers, and 7-day incidence rates. “There was a lot of confusion about which indicators are important: Should we look at deaths? Should we look at people in hospitals? Should we look at the number of tests conducted?” said the technical lead.
The decision to include some statistical indicators over others stirred up debate within BR’s newsroom. For instance, reporting total case numbers needed to be weighted against not being able to mention all the mild and asymptomatic cases that went unrecorded. Another caveat related to the number of beds available in intensive care units: “The number of beds doesn’t tell you much because you need staff — medical trained staff — to man those beds,” said the technical lead with the AI + Automation team. He specified that, at times, some hospitals were under strain because they could not supply these available beds with enough expert medical staff.
The team in charge of automated news at Tamedia faced a similar set of challenges as they had to rely on local Swiss cantons instead of the federal government to get data. “The federal government wasn’t really able to provide structured data in a machine-readable way and in a reliable way,” said a project lead at Tamedia. The cantons collected and presented data in an accessible manner. But the downside of having to rely on such a wide range of local sources is that journalists need to keep a close watch at how they evolve. “All the journalists in Switzerland who provide automated data reporting for the COVID crisis, they have to constantly think, rethink, and update their data sources,” said the project lead.
These statistical roundups were also sometimes prevented from going into full-on automation mode because of a disconnect between generating text and integrating them into a CMS. At The Times, automated text, unlike graphics, needed to be generated manually on a separate webpage, then pasted and copied into the newspaper’s CMS after undergoing editorial checks, a process described by the data and interactive journalist at the newspaper as “a bit of a halfway house.” For its part, the tool built at CP required journalists spread out all over Canada to enter new figures for their province or territory in a shared spreadsheet. “All the reporters have to do is go in and type in the new numbers,” said a journalist-developer who configured the tool. These numbers were then exported as JSON files and transformed into automated stories and graphics every time a journalist would request it on a separate webpage.
At The Times, this separation between automated text generation and the newspaper’s CMS was seen as a hurdle, as the numbers might already be outdated by the time they were ready for editorial check. According to the data and interactive journalist, not being able to simply change the numbers in the copy felt like “a real pinch point.” The data and interactive team eventually got permission to republish the story just with new numbers, as long as they would still go through editorial check if the lead of the story changed, for instance when the epicenter of the pandemic moved from China to Europe. Similarly, having to generate automated news separately on a webpage was seen as a drawback at CP. “It’s annoying to do the copy and paste, and that’s sort of the limit of where our technology is,” said the journalist-developer. He stressed that this should be solved with the adoption of a new CMS: “We’ll have API access to the content management system, so we won’t even have to have these webpages,” he said, indicating that automated stories could even be generated using a simple Slack command.
b. Using automation to develop new workflows during the pandemic
Some newsrooms used the pandemic as an opportunity to develop new automated workflows or tweak existing ones. At the British news agency RADAR, journalists directly contribute to every step of designing and implementing automated workflows. This ranges from finding storylines in newly published datasets to authoring templates using a third-party tool to generate their own automated stories. In the case of Bloomberg News, automated news stories are connected to an AI-powered system that extracts relevant information on companies’ statements and analyzes them through “knowledge graphs” that help prepare various scenarios, using Bloomberg’s own internal data. These scenarios are then run live to produce automated news in multiple languages. Although this new journalistic procedure involves machine-learning elements at the event detection and analysis stages, writing scripts in advance to prepare each of these scenarios remains largely a human effort.
These reconfigured newsroom workflows were demonstrated to be robust enough to handle the data deluge that followed the spread of the virus. Usually, the team at RADAR would work on one or two projects a day, but the COVID-19 pandemic reshuffled the deck to four or five projects a day, “just because there is so much data coming out,” said an editor at the news agency. This briefly put the newsroom under pressure due to resourcing issues, but also gave the team an opportunity to demonstrate their expert knowledge of automated news, which resulted in more clients being interested in RADAR’s other automated stories. Being part of a major company that specializes in technology and data gave Bloomberg News a head start and meant they had access to valuable resources: “We had a lot of datasets and a lot of procedures and a lot of technology available, so we were able to shift very, very quickly to the new environment, to the new topics,” said an executive in charge of newsroom AI and technology at Bloomberg. To report on the economic impacts of the pandemic, the news agency made notable use of alternate datasets to generate automated news. These included figures such as metro ridership, flight reservations, restaurant bookings, or supermarket visits. “We have all these really interesting snippets of data where, when you combine it for different countries, you can find a very interesting sort of real-time dataset that comes ahead of some of the country’s economic data,” said the executive.
The second type of newsroom workflow involved journalists directly working with automated news, while using them as a draft for their own stories. To provide reporters at HS with fresh updates on the state of the pandemic, an algorithm programmed by the newspaper’s data team connected every morning to an API set up by the Finnish Institute for Health and Welfare: “It goes to the newest COVID numbers and then creates short pieces of text and sends them to Slack to inform the reporters,” said a data journalist at HS, who was involved in designing the computer software. She specified that journalists can publish these automated stories as-is or tweak them before publication. In the same way, journalists at the Swedish news service Omni turned to automated content provider United Robots to equip them with a breaking-news desk that delivered regular updates on COVID-19. United Robots’ software connects to 24 curated sources via APIs and RSS feeds, or scrapes content associated with keywords on each of these websites. Every time an automated story is generated, an alert with a link to that story is sent on a Slack channel used by the newsroom, so that journalists can use this information in their own reporting. United Robots regularly updates its sources based on Omni’s suggestions to ensure its system remains current.

 Above: HS and Omni use an alert system through Slack that provides journalists with automated text to include wholly or partially in their copy, or forwards them a link to an automated story they can use in their own reporting. (Sources: HS and Omni)
Above: HS and Omni use an alert system through Slack that provides journalists with automated text to include wholly or partially in their copy, or forwards them a link to an automated story they can use in their own reporting. (Sources: HS and Omni)
Both HS and Omni experienced difficulties in accessing local data initially, which led them to seek out algorithmic solutions to remedy that. “We didn’t really have those kinds of extremely local news sources or health agency sources,” said a managing editor at Omni. Her only regret is that they adopted this automated dashboard a bit too late, once every local new case of COVID-19 was no longer considered to be breaking news. “For a long time, one single death somewhere was something that we wanted to send a push notification on,” she said. Access to local sources was also considered to be an issue in Finland, where prior to the launch of the governmental API, reporters had to manually retrieve information from the 21 websites that represented each of the country’s health areas. “Basically, somebody had to sit in front of their computer and refresh some pages to see if there are new numbers or not,” said the data journalist at HS.

In this chapter, I highlighted how these nine organizations used automated news on COVID-19 to provide a statistical overview of the spread of the virus through user-facing interfaces and new media products, or turned to new forms of newsroom workflows structured around the use of this technology, which eventually passed the test of a global pandemic. In the following section, I will detail some of the key challenges they faced and the solutions they found to remedy these.
Covering COVID-19 with automated news in practice
a. Challenges of relying on external datasets
Deploying automated news in a time of pandemic went together with a specific set of challenges that had to do with having to rely on external datasets to automate the coverage of the virus. This was the case in newsrooms trying to get data from several levels of government, as in Canada. “It’s hard to get this data from multiple governments: they all put it up in a different fashion, they put it up at different times,” said the journalist-developer working on automation at CP. In the United Kingdom, The Times grappled with the same lack of cohesive efforts to release data: “England, Scotland, Wales, and Northern Ireland all publish it in different ways,” said the data and interactive journalist at the newspaper, adding that this made comparisons between regions even more difficult. For its part, the news agency NTB faced an even bigger challenge: “Every Norwegian municipality has a different way of providing the data on their own pages. So it’s like 356 municipalities, and they have 356 different ways of sharing the data,” said a chief development officer at NTB.
Questions around data source selection also came into consideration when working with several levels of government. The project lead at Tamedia pointed out that, at the beginning of the outbreak, they needed to choose between data released by some of the Swiss cantons, which, in some cases, accounted for deaths in elderly care that were likely to be caused by COVID-19, and data from the Federal Office of Public Health, which focused only on laboratory-confirmed deaths. “There’s no right or wrong, but what you need to do is you need to be very transparent about which datasets you use,” he said.
Another challenge of relying on external datasets to automate COVID-19 stories had to do with erroneous data and sudden changes of format. First, data published by health and governmental bodies could prove to be inaccurate. “Sometimes the data has been wrong and they’re not corrected,” said an editor at NTB; this could be even more problematic when it concerned the number of patients who have died from the virus. In case of new data appearing to be wrong, BR’s COVID-19 newsletter would display numbers from the day before, along with a warning stressing that the figures were outdated. BR’s technical lead explained that should any errors make their way into the newsletter, they would fix them and then issue a correction statement. Another reason that could cause the newsletter to fail is when the API provided by the Robert Koch Institute stops working.
Sudden changes of format were also considered to be a major obstacle in automating the coverage of the virus. According to the journalist at The Times, the data structure used by Public Health England seemed to change every half an hour. “It was really difficult to rely on them as a source,” he said. The news agency NTB faced a similar problem with structured datasets or APIs released by municipal governments in Norway. “The sources might start reporting it differently or make adjustments. That’s a challenge,” said the editor at NTB.
On their end, the data team at HS experienced similar difficulties while working with the afternoon data, which the Finnish Institute for Health and Welfare released in an HTML table format. “It’s terrible, the website where this information is published,” said the data journalist at HS, explaining that the table’s structure kept changing all the time, for instance when the number of patients hospitalized was being moved from one column to another, making it very hard to use for automated news. Also, these changes seemed to occur at the end of the working week, making the team work overtime on Friday evenings to ensure there would be no technical issues over the weekend. “I tried to believe that they are not doing it on purpose: they are just humans and they want to have things done before the weekend comes,” said the data journalist with a touch of humor.
Finally, releasing data too soon or too late also came into consideration when working with external datasets to generate automated news on the spread of the disease. Some media organizations occasionally reported a lag in releasing data on the pandemic, resulting in numbers accumulating over a few days before being published all at once with more up-to-date data. “In today’s numbers, they might publish some deaths for a week ago,” said the editor at RADAR, who cautioned that reporters then needed to be extra careful when reporting differences between each of these dates. On her end, the managing editor at Omni observed that, in Sweden, this lag generally occurs over the weekend, when statistical services in hospitals are closed, leading to a significant spike in numbers at the beginning of the week. “At the beginning, I think we all were like, ‘Wow, that’s so many deaths in 24 hours.’ And then we realized that, well, it’s from maybe the past week,” she said.
On the other side of the coin, news organizations could also get the latest COVID-19 numbers before any official announcement, while connecting to an API service set up by governments or health authorities. “Sometimes we have actually managed to kind of beat, so to speak, the local health sources on their own news,” said the managing editor at Omni, whose automated dashboard connects to these kinds of sources. This could nevertheless raise new ethical questions, such as evaluating whether information published through APIs is considered to be public domain.
b. Developing ad hoc solutions as a remedy
To overcome the challenges of having to rely on external datasets to cover COVID-19 with automated news, media practitioners with a strong computing background developed ad hoc solutions to work around those. To work with data being released in various time zones, the journalist-developer at CP set up a shared spreadsheet that involved the participation of journalists in all Canadian provinces and territories. “It’s not just one person who’s doing all the work — it’s spread out across people all across the country and different times,” said the journalist-developer. Journalists must manually add new numbers to the shared spreadsheet, so that they can be exported as JSON files into a script that generates automated news every time a journalist requests it on a separate webpage.
This relatively rudimentary approach was largely effective, although it was not entirely failsafe. “Multiple times we’ve got, like, ‘Emergency! Emergency!’” said the journalist-developer. “Somebody copied and pasted in something that wasn’t a number and then all the calculations stopped working.” He also referred to journalists inserting numbers as decimals instead of as integers, or adding commas, which would make the spreadsheet crash. “I guess one of the downsides of a simple tool is people think they understand it and … you know, they just won’t read the instructions,” he said.
Another ad hoc solution involved the development of an alert system to work with tight deadlines and sudden changes of format. The data and interactive journalist at The Times noted that his team had to come to grips with Public Health England releasing data on COVID-19 unevenly at the end of the day, generally between 4 p.m. and 7 p.m. but sometimes as late as 10 p.m. To avoid journalists having to frequently refresh the page, the team set up an alert algorithm that checks if the database that is available online if the date corresponds to that of today’s. If that is the case, it sends a notification into Slack to inform journalists that new data is out, so that they can generate their own automated news and graphics on the webpage that was built for this purpose.
A similar system was set up in Finland at HS, but rather to guard against any mistake resulting from frequent changes of format within the data source. Whereas morning updates on COVID-19 are released through a central and structured API, afternoon updates are published as an HTML table whose structure changes all the time, according to the data journalist at HS. This makes scraping content for automated news unreliable, necessitating an extra verification step. “Somebody needs to check that the numbers are really correct,” said the data journalist. Her team therefore set up an alert algorithm that sends a notification to Slack every time the numbers are updated, which informs journalists that they need to retrieve the numbers manually and enter them into a shared spreadsheet that can then be used to generate automated news.
Lastly, keeping historical records to make calculations and be better accountable also helped newsrooms overcome the challenges of having to rely on external datasets to generate automated news on COVID-19. The lack of historical insights in the statistics released by the Finnish Institute for Health and Welfare prompted the data team at HS to store every new piece of information they could, so that they could compile their own calculations. “We want to track how the situation has evolved since the last seven days, how that compares to the seven days before that. At first, we didn’t have that because the authorities only published the snapshot ‘What’s the situation today,’” said the data journalist at HS. She recommended saving data figures as soon as possible, because a two-week wait is then needed before starting to make weekly comparisons.
In the United Kingdom, journalists at RADAR also grappled with a lack of historical data in the statistics released by health authorities, which became an incentive for them to keep track of all the numbers they used and to come up with their own calculations. According to the RADAR editor, this eventually resulted in making the newsroom more accountable: “Things are changed later down the line by the body that published them. So you’ve got to be defensible in why you’ve reported the story, and you’ve got to have a very clear understanding of absolutely everything in that data,” he said.
In this section, I provided a rundown of some of the challenges that newsrooms faced when using automated news to cover COVID-19, which demonstrated the difficulties associated with having to rely on external datasets. To remedy that, media practitioners with a strong computing background have created their own ad hoc solutions, such as using a shared spreadsheet to split up tasks across teams, setting up an alert system to inform journalists when new data are available, and keeping track of historical data for future reference.
The ad hoc solutions that editorial staff have developed to work around the challenges of having to rely on external datasets to cover COVID-19 with automated news demonstrate the importance for media practitioners to be able to solve problems through applying computing skills, a form of knowledge commonly known as computational thinking or computational journalism in a newsroom setting. This type of mindset has given journalists a considerable edge in deploying automated news quickly and efficiently in the midst of a global pandemic, but may also fuel ideas for the next iteration of these products. Based on this report’s findings, such an iteration could include features like a shared spreadsheet to split up work across teams, an alert system to check whether new data has been released, and a cloud storage service to keep track of historical data.
All in all, these ad hoc solutions designed around the use of automated news that were generated in-house or through a third-party provider seemed to involve levels of algorithmic programming that editorial staff can comprehend. Although the template-based approaches that they are building on are sometimes criticized for being too formulaic and less enjoyable to read than human-written news, they can at least be tweaked to achieve editorial goals. The more media practitioners engage with this tinkering of automated news systems, the more they develop their programmatic skills and thus reinforce their ability to exert control and have a say over the computational turn that journalism is taking.
At the other end of the spectrum, delegating the production of automated news to external content providers that use advanced machine-learning techniques could, on the one hand, result in generating more compelling pieces of news, but on the other hand, may also prove too complex for editorial staff to handle the nitty-gritty aspects associated with these systems. This could result in technological firms holding more influence over the future of journalism, unless media practitioners’ input is being sought on a continuous basis, for instance through collaborative workflows where journalists are trained in elements of machine learning and where technologists get a good grasp of journalism practice. These back-and-forth discussions may be especially instructive when it comes to encoding hard-to-measure features of journalism, such as a reporter’s “gut feeling” or ethical considerations that can include algorithmic biases.
Whether this concerns template-based systems or advanced machine learning models, it is essential that media managers and executives maintain core journalistic routines such as letting journalists conduct complementary interviews or on-the-spot forms of reporting, and do not solely focus on an exclusive use of automated news in their media strategy. Indeed, journalists exercising the critical thinking that goes with these activities in a man-machine marriage, for instance, could result in quality content being produced at a faster pace, whereas automated news alone could hardly be differentiated from a competitor’s when produced at a massive scale and ultimately hinder the organization’s position in SEO rankings. Moreover, keeping journalists connected with these routines will ensure that journalism standards that can be encoded into the creation of automated news will remain current and relevant, thus reinforcing the overall computational dimensions of journalism.
References
Carlson, M. (2015) The Robotic Reporter. Digital Journalism, 3, 416–431. doi: 10.1080/21670811.2014.976412
Diakopoulos, N. (2019). Automating the News: How Algorithms Are Rewriting the Media. Cambridge, MA: Harvard University Press.
Graefe, A. (2016). Guide to Automated Journalism (Research paper, Tow Center for Digital Journalism). Retrieved from https://academiccommons.columbia.edu/doi/10.7916/D80G3XDJ
Graefe A. & Bohlken N. (2020). Automated journalism: A meta-analysis of readers’ perceptions of human-written in comparison to automated news. Media and Communication, 8, 50–59. doi: 10.17645/mac.v8i3.3019
Danzon-Chambaud S. (2021). A systematic review of automated journalism scholarship: guidelines and suggestions for future research [version 1; peer review: 2 approved]. Open Research Europe, 1. doi: 10.12688/openreseurope.13096.
Dörr, K. (2016). Mapping the field of Algorithmic Journalism. Digital Journalism, 4, 700–722. doi: 10.1080/21670811.2015.1096748
Lindén, C.-G. (2017). Decades of Automation in the Newsroom. Digital Journalism, 5, 123–140. doi: 10.1080/21670811.2016.1160791
Acknowledgments
Thanks to my interviewees for their enthusiasm in participating in this research project and for answering all the follow-up questions I had. Thanks also to my PhD supervisor, Alessio Cornia, for helping me coordinate this work with my overall PhD thesis and to the Tow Center’s research director, Pete Brown, for his encouragement and valuable input. I’m also grateful to Mattia Peretti, JournalismAI manager at the LSE’s journalism think tank, Polis, for helping me reach out to some of the people I needed to talk to for this research project.
Funding
This Project was funded by the Knight News Innovation Fellowship and the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 765140.
Samuel Danzon-Chambaud is a Knight News Innovation fellow for the Tow Center for Digital Journalism