In late 2011, in a nearly 6,000-word article in The New York Times Magazine, health writer Tara Parker-Pope laid out the scientific evidence that maintaining weight loss is a nearly impossible task—something that, in the words of one obesity scientist she quotes, only “rare individuals” can accomplish. Parker-Pope cites a number of studies that reveal the various biological mechanisms that align against people who’ve lost weight, ensuring that the weight comes back. These findings, she notes, produce a consistent and compelling picture by “adding to a growing body of evidence that challenges conventional thinking about obesity, weight loss, and willpower. For years, the advice to the overweight and obese has been that we simply need to eat less and exercise more. While there is truth to this guidance, it fails to take into account that the human body continues to fight against weight loss long after dieting has stopped. This translates into a sobering reality: once we become fat, most of us, despite our best efforts, will probably stay fat.”
But does this mean the obese should stop trying so hard to lose weight? Maybe. Parker-Pope makes sure to include the disclaimer that “nobody is saying” obese people should give up on weight loss, but after spending so much time explaining how the science “proves” it’s a wasted effort, her assurance sounds a little hollow.
The article is crammed with detailed scientific evidence and quotes from highly credentialed researchers. It’s also a compelling read, thanks to anecdotal accounts of the endless travails of would-be weight-losers, including Parker-Pope’s own frustrating failures to remove and keep off the extra 60 pounds or so she says she carries.
In short, it’s a well-reported, well-written, highly readable, and convincing piece of personal-health-science journalism that is careful to pin its claims to published research.
There’s really just one problem with Parker-Pope’s piece: Many, if not most, researchers and experts who work closely with the overweight and obese would pronounce its main thesis—that sustaining weight loss is nearly impossible—dead wrong, and misleading in a way that could seriously, if indirectly, damage the health of millions of people.
Many readers—including a number of physicians, nutritionists, and mental-health professionals—took to the blogs in the days after the article appeared to note its major omissions and flaws. These included the fact that the research Parker-Pope most prominently cites, featuring it in a long lead, was a tiny study that required its subjects to go on a near-starvation diet, a strategy that has long been known to produce intense food cravings and rebound weight gain; the fact that many programs and studies routinely record sustained weight-loss success rates in the 30-percent range; and Parker-Pope’s focus on willpower-driven, intense diet-and-exercise regimens as the main method of weight loss, when most experts have insisted for some time now that successful, long-term weight loss requires permanent, sustainable, satisfying lifestyle changes, bolstered by enlisting social support and reducing the temptations and triggers in our environments—the so-called “behavioral modification” approach typified by Weight Watchers, and backed by research studies again and again.
Echoing the sentiments of many experts, Barbara Berkeley, a physician who has long specialized in weight loss, blogged that the research Parker-Pope cites doesn’t match reality. “Scientific research needs to square with what we see in clinical practice,” she wrote. “If it doesn’t, we should question its validity.” David Katz, a prominent physician-researcher who runs the Yale Prevention Research Center and edits the journal Childhood Obesity, charged in his Huffington Post blog that Parker-Pope, by listing all the biological mechanisms that work against weight loss, was simply asking the wrong question. “Let’s beware the hidden peril of that genetic and biological understanding,” he wrote. “It can be hard to see what’s going on all around you while looking through the lens of a microscope.” In fact, most of us know people—friends, family members, colleagues—who have lost weight and kept it off for years by changing the way they eat and boosting their physical activity. They can’t all be freaks of biology, as Parker-Pope’s article implies.
The Times has run into similar trouble with other prominent articles purporting to cut through the supposed mystery of why the world keeps getting dangerously fatter. One such piece pointed the finger at sugar and high-fructose corn syrup, another at bacteria. But perhaps the most controversial of the Times’s solution-to-the-obesity-crisis articles was the magazine’s cover story in 2002, by science writer Gary Taubes, that made the case that high-fat diets are perfectly slimming—as long as one cuts out all carbohydrates. His article’s implicit claim that copious quantities of bacon are good for weight loss, while oatmeal, whole wheat, and fruit will inevitably fatten you up, had an enormous impact on the public’s efforts to lose weight, and to this day many people still turn to Atkins and other ultra-low-carb, eat-all-the-fat-you-want diets to try to shed excess pounds. Unfortunately, it’s an approach that leaves the vast majority of frontline obesity experts gritting their teeth, because while the strategy sometimes appears to hold up in studies, in the real world such dieters are rarely able to keep the weight off—to say nothing of the potential health risks of eating too much fat. And of course, the argument Taubes laid out stands in direct opposition to the claims of the Parker-Pope article. Indeed, most major Times articles on obesity contradict one another, and they all gainsay the longstanding consensus of the field.
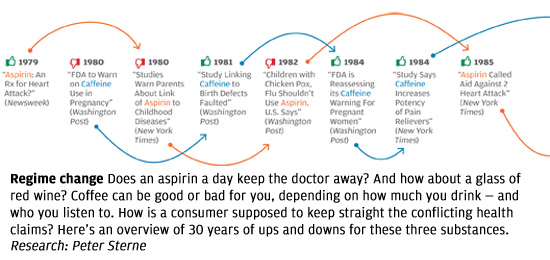
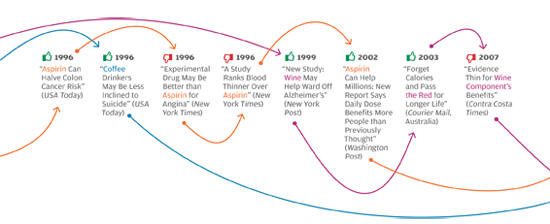
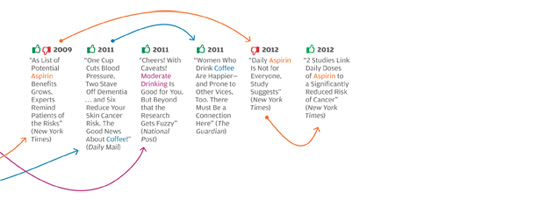
The problem isn’t unique to the Times, or to the subject of weight loss. In all areas of personal health, we see prominent media reports that directly oppose well-established knowledge in the field, or that make it sound as if scientifically unresolved questions have been resolved. The media, for instance, have variously supported and shot down the notion that vitamin D supplements can protect against cancer, and that taking daily and low doses of aspirin extends life by protecting against heart attacks. Some reports have argued that frequent consumption of even modest amounts of alcohol leads to serious health risks, while others have reported that daily moderate alcohol consumption can be a healthy substitute for exercise. Articles sang the praises of new drugs like Avastin and Avandia before other articles deemed them dangerous, ineffective, or both.
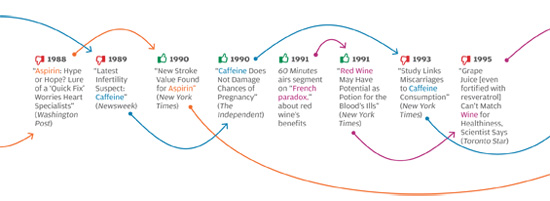
What’s going on? The problem is not, as many would reflexively assume, the sloppiness of poorly trained science writers looking for sensational headlines, and ignoring scientific evidence in the process. Many of these articles were written by celebrated health-science journalists and published in respected magazines and newspapers; their arguments were backed up with what appears to be solid, balanced reporting and the careful citing of published scientific findings.
But personal-health journalists have fallen into a trap. Even while following what are considered the guidelines of good science reporting, they still manage to write articles that grossly mislead the public, often in ways that can lead to poor health decisions with catastrophic consequences. Blame a combination of the special nature of health advice, serious challenges in medical research, and the failure of science journalism to scrutinize the research it covers.
Personal-health coverage began to move to the fore in the late 1980s, in line with the media’s growing emphasis on “news you can use.” That increased attention to personal health ate into coverage of not only other science, but also of broader healthcare issues. A 2009 survey of members of the Association of Health Care Journalists found that more than half say “there is too much coverage of consumer or lifestyle health,” and more than two-thirds say there isn’t enough coverage of health policy, healthcare quality, and health disparities.
The author of a report based on that survey, Gary Schwitzer, a former University of Minnesota journalism researcher and now publisher of healthcare-journalism watchdog HealthNewsReview.org, also conducted a study in 2008 of 500 health-related stories published over a 22-month period in large newspapers. The results suggested that not only has personal-health coverage become invasively and inappropriately ubiquitous, it is of generally questionable quality, with about two-thirds of the articles found to have major flaws. The errors included exaggerating the prevalence and ravages of a disorder, ignoring potential side effects and other downsides to treatments, and failing to discuss alternative treatment options. In the survey, 44 percent of the 256 staff journalists who responded said that their organizations at times base stories almost entirely on press releases. Studies by other researchers have come to similar conclusions.
Thoughtful consumers with even a modest knowledge of health and medicine can discern at a glance that they are bombarded by superficial and sometimes misleading “news” of fad diets, miracle supplements, vaccine scares, and other exotic claims that are short on science, as well as endlessly recycled everyday advice, such as being sure to slather on sun protection. But often, even articles written by very good journalists, based on thorough reporting and highly credible sources, take stances that directly contradict those of other credible-seeming articles.
There is more at stake in these dueling stories than there would be if the topic at hand were, say, the true authorship of Shakespeare’s plays. Personal healthcare decisions affect our lifespan, the quality of our lives, and our productivity, and the result—our collective health—has an enormous impact on the economy. Thirty years ago, misleading health information in the press might not have been such a problem, since at the time physicians generally retained fairly tight control of patient testing and treatment decisions. Today, however, the patient is in the driver’s seat when it comes to personal health. What’s more, it is increasingly clear that the diseases that today wreak the most havoc—heart disease, cancer, diabetes, and Alzheimer’s—are most effectively dealt with not through medical treatment, but through personal lifestyle choices, such as diet, exercise, and smoking habits.
Consider the potential damage of bad weight-loss-related journalism. Obesity exacerbates virtually all major disease risks—and more than one in 20 deaths in the US is a premature death related to obesity, according to a 2007 Journal of the American Medical Association study. Obesity carries an annual price tag of as much as $5,000 a year in extra medical costs and lost productivity, for a total cost to the US economy of about $320 billion per year—a number that could quadruple within 10 years as obesity rates climb, according to some studies. (There is, of course, a lot of uncertainty in cost projections, and this research does not account for the impact of the Affordable Care Act.) On top of these costs are the subjective costs of the aches, discomforts, and compromised mobility associated with obesity.
Meanwhile, there’s a wide range of convincing-sounding yet wildly conflicting weight-loss-related claims made by prominent science journalists. People who might otherwise be able to lose weight on the sort of sensible, lifestyle-modification program recommended by most experts end up falling for the faddish, ineffective approaches touted in these articles, or are discouraged from trying at all. For example, innumerable articles (including Parker-Pope’s Times piece) have emphasized the notion that obesity is largely genetically determined. But study after study has shown that obesity tends to correlate to environment, not personal genome, as per the fact that people who emigrate from countries with traditionally low obesity rates, such as China, tend to hew to the obesity rates of their adopted countries. What’s more, global obesity rates are rapidly rising year by year, including in China, whereas the human genome barely changes over thousands of years. And studies clearly show that “obesity genes” are essentially neutralized by healthy behaviors such as exercise.
It is not encouraging to those trying to muster the focus and motivation to stick to a healthy-eating-and-exercise program to hear that their obesity is largely genetically determined, suggesting—sometimes explicitly—that the obese are doomed to remain so no matter what they do. A 2011 New England Journal of Medicine study (as reported in The New York Times) found that people tend to binge after they find out they carry a supposed fat-promoting gene. Other studies have shown—in keeping with common sense—that one of the best predictors of whether someone starting a weight-loss program will stick with it is how strongly the person believes it will succeed. When journalists erode that confidence with misleading messages, the results are easy to predict.
When science journalism goes astray, the usual suspect is a failure to report accurately and thoroughly on research published in peer-reviewed journals. In other words, science journalists are supposed to stick to what well-credentialed scientists are actually saying in or about their published findings—the journalists merely need to find a way to express this information in terms that are understandable and interesting to readers and viewers.
But some of the most damagingly misleading articles don’t stem from the reporter’s failure to do this. Rather, science reporters—along with most everyone else—tend to confuse the findings of published science research with the closest thing we have to the truth. But as is widely acknowledged among scientists themselves, and especially within medical science, the findings of published studies are beset by a number of problems that tend to make them untrustworthy, or at least render them exaggerated or oversimplified.
It’s easy enough to verify that something is going wrong with medical studies by simply looking up published findings on virtually any question in the field and noting how the findings contradict, sometimes sharply. To cite a few examples out of thousands, studies have found that hormone-replacement therapy is safe and effective, and also that it is dangerous and ineffective; that virtually every vitamin supplement lowers the risk of various diseases, and also that they do nothing for these diseases; that low-carb, high-fat diets are the most effective way to lose weight, and that high-carb, low-fat diets are the most effective way to lose weight; that surgery relieves back pain in most patients, and that back surgery is essentially a sham treatment; that cardiac patients fare better when someone secretly prays for them, and that secret prayer has no effect on cardiac patients. (Yes, these latter studies were undertaken by respected researchers and published in respected journals.)
Biostatisticians have studied the question of just how frequently published studies come up with wrong answers. A highly regarded researcher in this subfield of medical wrongness is John Ioannidis, who heads the Stanford Prevention Research Center, among other appointments. Using several different techniques, Ioannidis has determined that the overall wrongness rate in medicine’s top journals is about two thirds, and that estimate has been well-accepted in the medical field.
A frequent defense of this startling error rate is that the scientific process is supposed to wend its way through many wrong ideas before finally approaching truth. But that’s a complete mischaracterization of what’s going on here. Scientists might indeed be expected to come up with many mistaken explanations when investigating a disease or anything else. But these “mistakes” are supposed to come in the form of incorrect theories—that a certain drug is safe and effective for most people, that a certain type of diet is better than another for weight loss. The point of scientific studies is to determine whether a theory is right or wrong. A study that accurately finds a theory to be incorrect has arrived at a correct finding. A study that mistakenly concludes an incorrect theory is correct, or vice-versa, has arrived at a wrong finding. If scientists can’t reliably test the correctness of their theories, then science is in trouble—bad testing isn’t supposed to be part of the scientific process. Yet medical journals, as we’ve seen, are full of such unreliable findings.
Another frequent claim, especially within science journalism, is that the wrongness problems go away when reporters stick with randomized control trials (RCTs). These are the so-called gold standard of medical studies, and typically involve randomly assigning subjects to a treatment group or a non-treatment group, so that the two groups can be compared. But it isn’t true that journalistic problems stem from basing articles on studies that aren’t RCTs. Ioannidis and others have found that RCTs, too (even large ones), are plagued with inaccurate findings, if to a lesser extent. Remember that virtually every drug that gets pulled off the market when dangerous side effects emerge was proven “safe” in a large RCT. Even those studies of the effectiveness of third-party prayer were fairly large RCTs. Meanwhile, some of the best studies have not been rcts, including those that convincingly demonstrated the danger of cigarettes, and the effectiveness of seat belts.
Why do studies end up with wrong findings? In fact, there are so many distorting forces baked into the process of testing the accuracy of a medical theory, that it’s harder to explain how researchers manage to produce valid findings, aside from sheer luck. To cite just a few of these problems:
Mismeasurement To test the safety and efficacy of a drug, for example, what researchers really want to know is how thousands of people will fare long-term when taking the drug. But it would be unethical (and illegal) to give unproven drugs to thousands of people, and no one wants to wait 20 years for results. So scientists must rely on animal studies, which tend to translate poorly to humans, and on various short-cuts and indirect measurements in human studies that they hope give them a good indication of what a new drug is doing. The difficulty of setting up good human studies, and of making relevant, accurate measurements on people, plagues virtually all medical research.
Confounders Study subjects may lose weight on a certain diet, but was it because of the diet, or because of the support they got from doctors and others running the study? Or because they knew their habits and weight were being recorded? Or because they knew they could quit the diet when the study was over? So many factors affect every aspect of human health that it’s nearly impossible to tease them apart and see clearly the effect of changing any one of them.
Publication bias Research journals, like newsstand magazines, want exciting stories that will have impact on readers. That means they prefer studies that deliver the most interesting and important findings, such as that a new treatment works, or that a certain type of diet helps most people lose weight. If multiple research teams test a treatment, and all but one find the treatment doesn’t work, the journal might well be interested in publishing the one positive result, even though the most likely explanation for the oddball finding is that the researchers behind it made a mistake or perhaps fudged the data a bit. What’s more, since scientists’ careers depend on being published in prominent journals, and because there is intense competition to be published, scientists much prefer to come up with the exciting, important findings journals are looking for—even if it’s a wrong finding. Unfortunately, as Ioannidis and others have pointed out, the more exciting a finding, the more likely it is to be wrong. Typically, something is exciting specifically because it’s unexpected, and it’s unexpected typically because it’s less likely to occur. Thus, exciting findings are often unlikely findings, and unlikely findings are often unlikely for the simple reason that they’re wrong.
Ioannidis and others have noted that the supposed protection science offers to catch flawed findings—notably peer review and replication—is utterly ineffective at detecting most problems with studies, from mismeasurement to outright fraud (which, confidential surveys have revealed, is far more common in research than most people would suppose).
None of this is to say that researchers aren’t operating as good scientists, or that journals don’t care about the truth. Rather, the point is that scientists are human beings who, like all of us, crave success, status, and funding, and who make mistakes; and that journals are businesses that need readers and impact to thrive.
It’s one thing to be understanding of these challenges scientists and their journals face, and quite another to be ignorant of the problems they cause, or to fail to acknowledge those problems. But too many health journalists tend to simply pass along what scientists hand them—or worse, what the scientists’ PR departments hand them. Two separate 2012 studies of mass-media health articles, one published in PLoS Medicine and the other in The British Medical Journal, found that the content and quality of the articles roughly track the content and quality of the press releases that described the studies’ findings.
Given that published medical findings are, by the field’s own reckoning, more often wrong than right, a serious problem with health journalism is immediately apparent: A reporter who accurately reports findings is probably transmitting wrong findings. And because the media tend to pick the most exciting findings from journals to pass on to the public, they are in essence picking the worst of the worst. Health journalism, then, is largely based on a principle of survival of the wrongest. (Of course, I quote studies throughout this article to support my own assertions, including studies on the wrongness of other studies. Should these studies be trusted? Good luck in sorting that out! My advice: Look at the preponderance of evidence, and apply common sense liberally.)
What is a science journalist’s responsibility to openly question findings from highly credentialed scientists and trusted journals? There can only be one answer: The responsibility is large, and it clearly has been neglected. It’s not nearly enough to include in news reports the few mild qualifications attached to any study (“the study wasn’t large,” “the effect was modest,” “some subjects withdrew from the study partway through it”). Readers ought to be alerted, as a matter of course, to the fact that wrongness is embedded in the entire research system, and that few medical research findings ought to be considered completely reliable, regardless of the type of study, who conducted it, where it was published, or who says it’s a good study.
Worse still, health journalists are taking advantage of the wrongness problem. Presented with a range of conflicting findings for almost any interesting question, reporters are free to pick those that back up their preferred thesis—typically the exciting, controversial idea that their editors are counting on. When a reporter, for whatever reasons, wants to demonstrate that a particular type of diet works better than others—or that diets never work—there is a wealth of studies that will back him or her up, never mind all those other studies that have found exactly the opposite (or the studies can be mentioned, then explained away as “flawed”). For “balance,” just throw in a quote or two from a scientist whose opinion strays a bit from the thesis, then drown those quotes out with supportive quotes and more study findings.
Of course, journalists who question the general integrity of medical findings risk being branded as science “denialists,” lumped in with crackpots who insist evolution and climate change are nonsense. My own experience is that scientists themselves are generally supportive of journalists who raise these important issues, while science journalists are frequently hostile to the suggestion that research findings are rife with wrongness. Questioning most health-related findings isn’t denying good science—it’s demanding it.
Ironically, we see much more of this sort of skeptical, broad-perspective reporting on politics, where politicians’ claims and poll results are questioned and factchecked by journalists, and on business, where the views of CEOs and analysts and a range of data are played off against one another in order to provide a fuller, more nuanced picture.
Yet in health journalism (and in science journalism in general), scientists are treated as trustworthy heroes, and journalists proudly brag on their websites about the awards and recognition they’ve received from science associations—as if our goal should be to win the admiration of the scientists we’re covering, and to make it clear we’re eager to return the favor. The New York Times’s highly regarded science writer Dennis Overbye wrote in 2009 that scientists’ “values, among others, are honesty, doubt, respect for evidence, openness, accountability and tolerance and indeed hunger for opposing points of view.” But given what we know about the problems with scientific studies, anyone who wants to assert that science is being carried out by an army of Abraham Lincolns has a lot of explaining to do. Scientists themselves don’t make such a claim, so why would we do it on their behalf? We owe readers more than that. Their lives may depend on it.
David H. Freedman is a contributing editor at The Atlantic, and a consulting editor at Johns Hopkins Medicine International and at the McGill University Desautels Faculty of Management.