

Sign up for the daily CJR newsletter.
On March 15, Instagram posted a note on its blog that sent the internet into a frenzy: “To improve your experience, your feed will soon be ordered to show the moments we believe you will care about the most.” Panicked Instagram users protested, afraid their posts would get lost in the revised stream, and began posting pictures with the hashtag #turnmeon, pleading with followers to turn on notifications for their accounts. In response to the uproar, Instagram posted a tweet that amounted to, “Hey, calm down. We’re not changing the algorithm yet.”
At first glance, a tweak to the flow of narcissism and latte art is hardly a significant story. But there’s more at play here.
As online users, we’ve become accustomed to the giant, invisible hands of Google, Facebook, and Amazon feeding our screens. We’re surrounded by proprietary code like Twitter Trends, Google’s autocomplete, Netflix recommendations, and OKCupid matches. It’s how the internet churns. So when Instagram or Twitter, or the Silicon Valley titan of the moment, chooses to mess with what we consider our personal lives, we’re reminded where the power actually lies. And it rankles.
While internet users may be resigned to these algorithmic overlords, journalists can’t be. Algorithms have everything journalists are hardwired to question: They’re powerful, secret, and governing essential parts of society. Algorithms decide how fast Uber gets to you, whether you’re approved for a loan, whether a prisoner gets parole, who the police should monitor, and who the TSA should frisk.
‘Algorithms are like a very small child. They learn from their environment.’
They’re also anything but objective. “How can they be?” asks Mark Hansen, a statistician and the director of the Brown Institute at Columbia University. “They’re the products of human imagination.” (As an experiment, think about all of the ways you could answer the question: “How many Latinos live in New York?” That’ll give you an idea of how much human judgement goes into turning the real world into math.)
Algorithms are built to approximate the world in a way that accommodates the purposes of their architect, and “embed a series of assumptions about how the world works and how the world should work,” says Hansen.
It’s up to journalists to investigate those assumptions, and their consequences, especially where they intersect with policy. The first step is extending classic journalism skills into a nascent domain: questioning systems of power, and employing experts to unpack what we don’t know. But when it comes to algorithms that can compute what the human mind can’t, that won’t be enough. Journalists who want to report on algorithms must expand their literacy into the areas of computing and data, in order to be equipped to deal with the ever-more-complex algorithms governing our lives.
The reporting so far
Few newsrooms consider algorithms a beat of their own, but some have already begun this type of reporting.
Algorithms can generally be broken down into three parts: the data that goes in; the “black box,” or the actual algorithmic process; and the outcome, or the value that gets spit out, be it a prediction or score or price. Reporting on algorithms can be done at any of the three stages, by analyzing the data that goes in, evaluating the data that comes out, or reviewing the architecture of the algorithm itself to see how it reaches its judgements.
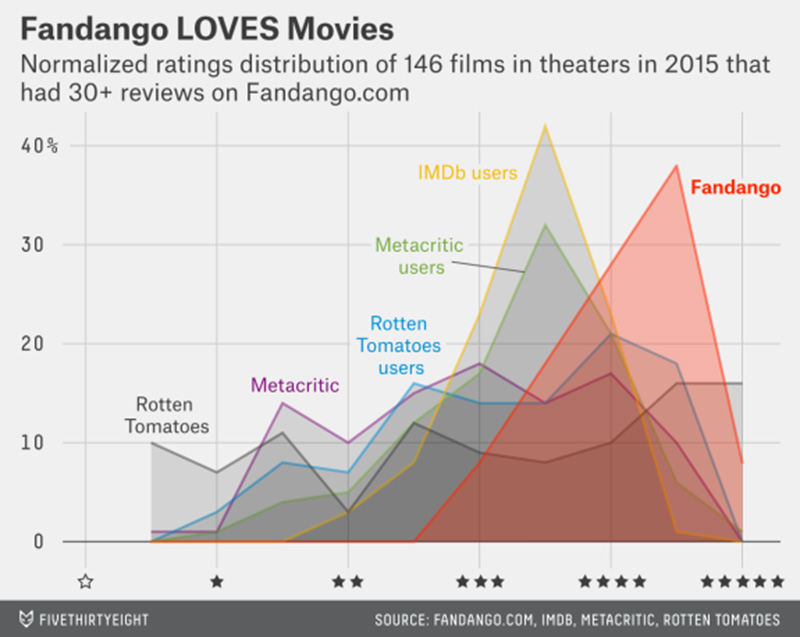
Currently, the majority of reporting on algorithms is done by looking at the outcomes and attempting to reverse-engineer the algorithm, applying similar techniques as are used in data journalism. The Wall Street Journal used this technique to find that Staples’ online prices were determined by the customer’s distance from a competitor’s store, leaving prices higher in rural areas. And FiveThirtyEight used the method to skewer Fandango’s movie ratings–which skewed abnormally high, rarely dipping below 3 stars–while a ProPublica analysis suggested that Uber’s surge pricing increases cost but not the supply of drivers.
While the previous stories directly analyzed algorithmic outcomes, many more report about them. On the criminal justice beat, for example, there has been a slew of stories on proprietary algorithms used by law enforcement: A program called Beware is helping Fresno police use Twitter data to assign residents a “threat score;” a California man is facing charges for a nearly 40-year-old rape because of a DNA match analyzed by TrueAllele software; even scientists don’t know the formula behind a test that scores suspected sex offenders; and police departments across the country are increasingly using predictive policing software like PredPol to decide where to send patrols.
In one such report, The New York Times wrote about a crop of banking startups using big data to rethink lending. Part of these startups’ (admirable) goal is to identify populations who have traditionally been ignored by lenders. To that end, one company said that instead of credit history, it uses factors like whether applicants type in ALL CAPS, as well as how much time they spent reading terms and conditions, to determine creditworthiness. The story introduces more questions than it answers, beginning with: Is this method really more equitable?
In fact, that’s a question that fuels much of the talk about algorithms.
Can an algorithm be racist?
“Algorithms are like a very small child,” says Suresh Venkatasubramanian. “They learn from their environment.”
Venkatasubramanian is a computer science professor at the University of Utah. He’s someone who thinks about algorithmic fairness, ever since he read a short story by Cory Doctorow published in 2006, called “Human Readable.” The story takes place in a future world, similar to ours, but in which all national infrastructure (traffic, email, the media, etc.) is run by “centralized emergent networks,” modeled after ant colonies. Or in other words: a network of algorithms. The plot revolves around two lovers: a network engineer who is certain the system is incorruptible, and a lawyer who knows it’s already been corrupted.
“It got me thinking,” says Venkatasubramanian. “What happens if we live in a world that is totally driven by algorithms?”
He’s not the only one asking that question. Algorithmic accountability is a growing discipline across a number of fields. Computer scientists, legal scholars, and policy wonks are all grappling with ways to identify or prevent bias in algorithms, along with the best ways to establish standards for accountability in business and government. A big part of the concern is whether (and how) algorithms reinforce or amplify bias against minority groups.
Algorithmic accountability builds on the existing body of law and policy aimed at combatting discrimination in housing, employment, admissions, and the like, and applies the notion of disparate impact, which looks at the impact of a policy on protected classes rather than its intention. What that means for algorithms is that it doesn’t have to be intentionally racist to have racist consequences.
Algorithms are built to approximate the world in a way that accommodates the purposes of their architect.
Algorithms can be especially susceptible to perpetuating bias for two reasons. First, algorithms can encode human bias, whether intentionally or otherwise. This happens by using historical data or classifiers that reflect bias (such as labeling gay households separately, etc.). This is especially true for machine-learning algorithms that learn from users’ input. For example, researchers at Carnegie Mellon University found that women were receiving ads for lower-paying jobs on Google’s ad network but weren’t sure why. It was possible, they wrote, that if more women tended to click on lower-paying ads, the algorithm would learn from that behavior, continuing the pattern.
Second, algorithms have some inherently unfair design tics–many of which are laid out in a Medium post, “How big data is unfair.” The author points out that since algorithms look for patterns, and minorities by definition don’t fit the same patterns as the majority, the results will be different for members of the minority group. And if the overall success rate of the algorithm is pretty high, it might not be noticeable that the people it isn’t working for all belong to a similar group.
To rectify this, Venkatasubramanian, along with several colleagues, wrote a paper on how computer scientists can test for bias mathematically while designing algorithms, the same way they’d check for accuracy or error rates in other data projects. He’s also building a tool for non-computer scientists, based on the same statistical principles, which scores uploaded data with a “fairness measure.” Although the tool can’t check if an algorithm itself is fair, it can at least make sure the data you’re feeding it is. Most algorithms learn from input data, Venkatasubramanian explains, so that’s the first place to check for bias.
Much of the reporting on algorithms thus far has focused on their impact on marginalized groups. ProPublica’s story on The Princeton Review, called “The Tiger-Mom Tax,” found that Asian families were almost twice as likely to be quoted the highest of three possible prices for an SAT tutoring course, and that income alone didn’t account for the pricing scheme. A team of journalism students at the University of Maryland, meanwhile, found that Uber wait times were longer in non-white areas in DC.
Bias is also the one of the biggest concerns with predictive policing software like PredPol, which helps police allocate resources by identifying patterns in past crime data and predicting where a crime is likely to happen. The major question, says Maurice Chammah, a journalist at The Marshall Project who reported on predictive policing, is whether it will just lead to more policing for minorities. “There was a worry that if you just took the data on arrests and put it into an algorithm,” he says, “the algorithm would keep sending you back to minority communities.”
Working backwards
Like any nascent field, reporting on algorithms comes with some inherent challenges. First, we still don’t have a coherent understanding of the effects of algorithms and, therefore, where to assign blame. If computers can’t be racist, who’s responsible if their output discriminates?
Journalists don’t have to answer these questions, but they do have to take them into account when doing analyses and reporting the conclusions.
In the two examples above, on The Princeton Review and Uber, the findings are, in all likelihood, simply a result of capitalism. ProPublica calls The Princeton Review finding an “unexpected result,” implying that the company was not using an “Asian” classifier as a factor in price quotes; and even a quick look at the Uber wait-time map that accompanies the story suggests it could just as easily be a heat map for demand. The reality of price discrimination might not be pleasant, but it’s perfectly legal if you’re not overtly discriminating against a protected class.
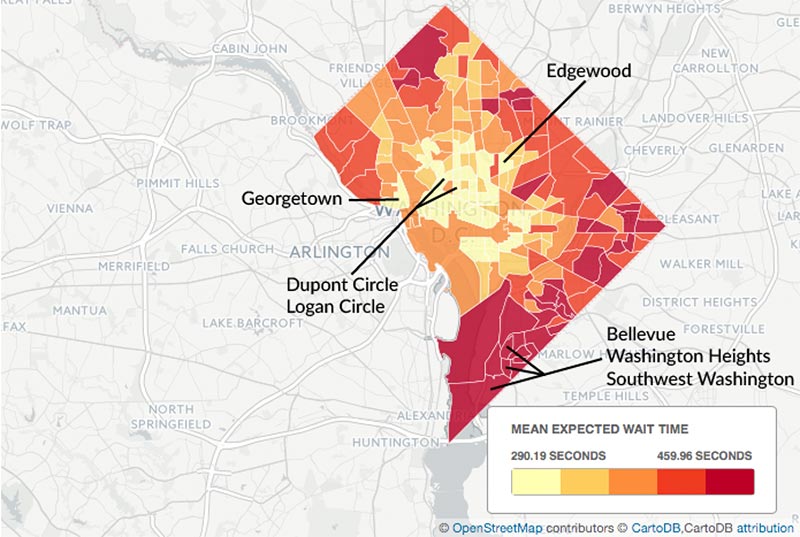
“It’s a lovely analysis,” says Jonathan Stray, a journalist who teaches computational journalism at Columbia’s Journalism School, of the Uber story, “but I have trouble interpreting the results.” The trouble is that it’s possible to stack race against any other factor and you’ll probably find some association, says Stray. That’s partly because many factors, like location and income, act as proxies for race, and those factors interact with each other in unexpected ways.
“You have to be careful with that kind of reasoning,” says Stray. Even though the Uber piece doesn’t assign blame, the takeaway seems to be that Uber is somehow at fault. “Does Uber have a responsibility to provide equal service?”
This is the limitation of working with data that’s spit out of an algorithm without knowing how that algorithms works.
ProPublica, for instance, checked the price for online SAT tutoring in every zip code in the US, then analyzed the data to find out which of many possible factors contributed to the difference in prices. This is different from methods used in most data analysis, as with the US Census or unemployment rates. With those datasets, you know where the data is coming from and how it was collected. That allows you to ask questions about the merits of the data itself, and know the limits of what your analysis can show. With algorithm outputs, even with sophisticated analyses, the most you can do is explain that something is happening, but not how.
To Jeff Larson, data editor at ProPublica and the author of “The Tiger-Mom Tax,” that’s not necessarily a bad thing. Like disparate impact, the important story is the one in which someone or some group is being adversely affected, regardless of motive.
“Not all stories have a bad guy,” says Larson. There doesn’t have to be someone out there “twirling their mustache” for there to be a story.
Inside the black box
But of course, working with outcomes isn’t the only available strategy. Instead of just looking at the effects of algorithms and trying to work backward, reporters should set their sights on the black box itself (remember, that’s the actual architecture of the algorithm).
Having access to the source code or the design of the algorithm provides a whole new level of insight. That’s clear from The Marshall Project’s reporting on predictive policing. In the piece titled “Policing the future,” Chammah, together with Hansen, reported on software called HunchLab, which is similar to the more widely used PredPol, with at least one major difference: It is much more transparent. Azavea, the company behind HunchLab, shared its methodology and models with The Marshall Project’s reporters.**
While the piece doesn’t go into the details of how the software works, it does address how both HunchLab and the police agencies implementing the software are grappling with concerns about computed policing. For example, HunchLab only maps violent crimes, not drug-related crimes, which is seen as an area of systemic racial disparity in the criminal justice system.
‘Not all stories have a bad guy.’ There doesn’t have to be someone out there ‘twirling their mustache’ for there to be a story.
The advantage of such access, says Chammah, was that it allowed for debate on the issues, rather than a meta debate on transparency. “The story became about getting to explore the kind of philosophical questions that are circulating around predictive policing,” he says.
But the black box is difficult to access, both conceptually and literally. Most algorithms, whether used by business or government, are proprietary, and it isn’t entirely clear what kinds of source codes would be available under FOIA. Several cases have gone to court, on FOIA grounds or otherwise, to access source codes or documents related to them, but most are thwarted by the trade secret exemption or security concerns.
In one FOIA case, the Electronic Privacy Information Center, a nonprofit organization in Washington, DC, requested documents for a system that assigns threat assessments to air and land passengers traveling in the US. The Analytic Framework of Intelligence, as it’s called, takes in data from a large collection of both governmental and nongovernmental databases, including internet feeds, and then spits out a risk assessment. The agency that runs the system, US Customs and Border Patrol, released several heavily redacted documents to EPIC after it was ordered to by a federal court. One file was filled with page after page of blacked-out screenshots of the application because, according to US Customs, an “individual knowledgeable in computer systems” could use the screenshots to hack the system. EPIC is back in court fighting the redactions.
Once the literal access problem is solved, then there’s the task of making sense of the code. Analyzing the code may require algorithmic knowledge that’s not currently part of the journalistic skill set and will require collaboration with those fluent in mathspeak or other creative formats.
Computer scientists, says Hansen, “are putting into code our society’s values and ethics,” and that process has to be out in the open so the public can participate.
In whatever form it takes, reporting on algorithms will likely become more of a required skill. Journalists need to up their game, both with respect to demanding algorithmic transparency, and in augmenting the current journalistic skill set so we can deal with humanity’s augmented intelligence.
To get started:
- “How big data is unfair“: A layperson’s guide to why big data and algorithms are inherently biased.
- “Algorithmic accountability reporting: On the investigation of black boxes“: The primer on reporting on algorithms, by Nick Diakopoulos, an assistant professor at the University of Maryland who has written extensively on the intersection of journalism and algorithmic accountability. A must-read.
- “Certifying and removing disparate impact“: The computer scientist’s guide to locating and and fixing bias in algorithms computationally, by Suresh Venkatasubramanian and colleagues. Some math is involved, but you can skip it.
- The Curious Journalist’s Guide to Data: Jonathan Stray’s gentle guide to thinking about data as communication, much of which applies to reporting on algorithms as well.
**An earlier version of this story stated that HunchLab is open source. In fact, HunchLab is built with open-source components but is not itself open source.
Has America ever needed a media defender more than now? Help us by joining CJR today.



