


Sign up for the daily CJR newsletter.
Does Palestine pay $350 million a year to terrorists and their families? Israeli Prime Minister Benjamin Netanyahu suggested as much in a speech he gave in the US last March, but it’s a murky and complex claim to confirm or rebut. Glenn Kessler, the editor of the Fact Checker blog at The Washington Post, spent nearly 2,500 words dissecting the statement in a post published about a week later. He was able to write the post relatively quickly because by the time he published it, Kessler had actually been working on that fact-check for seven weeks already, beginning long before it came out of Netanyahu’s mouth. He got a jump on the background research thanks to an algorithm that had given him a heads-up when a similar statement was made by an Israeli official on CNN in January.
That algorithm is called ClaimBuster. It’s used by the Duke University Tech & Check Cooperative to monitor CNN transcripts for claims that are fact-checkable—typically statements involving numbers—and send alerts about them to reporters. Every morning a list of “checkworthy” statements made on air is emailed to fact checkers at outlets such as The Washington Post and Politifact. Journalists then decide which to focus on—like the claim about the $350 million dollar payments that Kessler drilled into. Journalism still needs people to perform the difficult task of weeding through the hype, spin, and bias in ambiguous statements, but computers can help a lot with monitoring and spotting claims that might be deserving of journalists’ attention. It’s “a useful tip sheet that alerts us to things that we would have otherwise missed,” Kessler tells CJR.
Algorithmic claim spotting is one of a growing number of applications of computational story discovery. Whether monitoring political campaign donations, keeping an eye on the courts, surfacing newsworthy events based on social media posts, winnowing down hundreds of thousands of documents for an investigation, or identifying newsworthy patterns in large datasets, computational story discovery tools are helping to speed up and scale up journalists’ ability to surveil the world for interesting news stories. Algorithms offer a sort of data-driven sixth sense that can help orient journalistic attention.
Another early foray into computational story discovery is the Newsworthy tool, developed at Journalism++ in Sweden. The system monitors open government data and identifies statistically interesting leads based on anomalies, outliers, and trends in numerical data streams such as real estate prices, weather patterns, and crime reports, among others. These leads are adapted for different municipalities by putting local aberrations in context with national trends, which helps reporters pursue local angles. In the pilot deployment of the system, creator Jens Finnäs told me that it had distributed 30-100 news leads per dataset per month to journalists who were part of the beta-test network in Sweden.
It’s almost like having a robo-freelancer pitching a story that might be interesting to commission—a starting hook for further reporting.
Newsworthy users can subscribe to leads from various datasets to receive an alert when an interesting statistical pattern is found. It’s almost like having a robo-freelancer pitching a story that might be interesting to commission—a starting hook for further reporting. For instance, the figure below shows a lead produced by the system indicating that the number of asylum applicants from Pakistan to the EU had dropped between 2016 and 2018. It includes several summary sentences of text about the anomaly, plus a bar graph to provide visual evidence and context, and, perhaps most importantly, the data, which reporters can use to verify results for themselves.
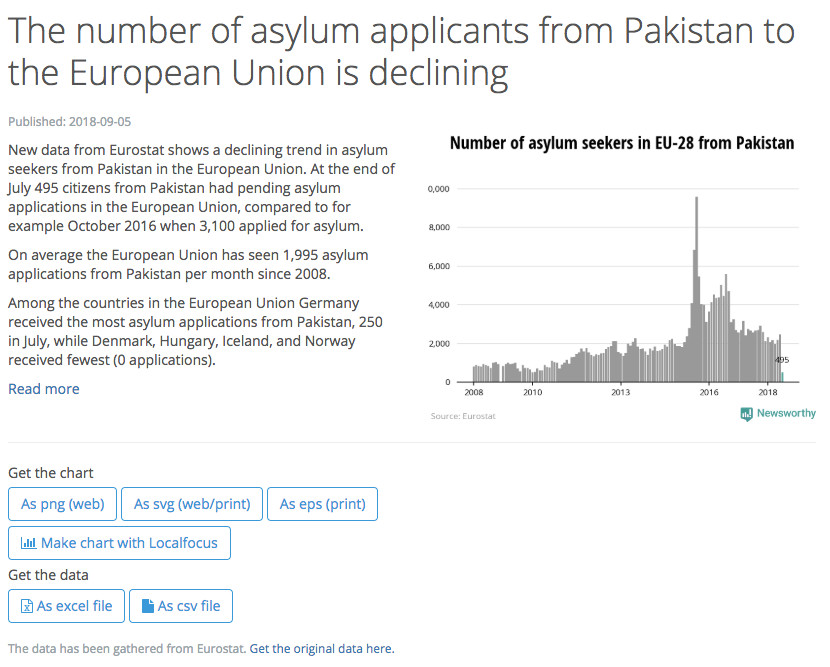
click image for larger version
Of course, there are still a number of challenges that make such tools difficult to incorporate in practice.
READ: The cruel image of “border protection”
A fundamental hurdle to building and using these tools effectively is articulating in algorithm form what kind of news you’re looking for. That means defining what is newsworthy—a difficult thing to pin down for an algorithm because it depends on a range of individual, organizational, social, ideological, cultural, economic, and technical forces. A story may need to fit with a publication’s editorial focus, agenda, or other organizational constraints, as well as with audience expectations. Context, including whether a story has already been covered and what other stories are currently getting attention in the media, are important factors. Newsworthiness is not intrinsic to an event. It arises out of a judgment process that humans—and now algorithms—contribute to.
In some cases newsworthiness might be defined explicitly in terms of rule-based patterns in the data: IF “outlier detected,” THEN “send alert.” In other cases, investigative journalists might tag a set of documents as “newsworthy” or “not newsworthy” and use machine learning techniques that allow new documents to be tagged automatically. But whether rule-based or data-driven, the definition of newsworthiness is very much scenario and topic-dependent. There is no one-size-fits-all algorithm for detecting newsworthiness in data.
So, to be useful in a variety of reporting scenarios, it helps if the story discovery algorithms permit a high degree of configurability in the user interface. Flexibility in defining which sources to monitor is key. The Tech & Check project, for instance, only monitors CNN transcripts, but if it could be configured to monitor NBC, Fox, and even statements on the floor of Congress, “that would be huge,” Kessler said. Within those transcripts, it would also be useful to filter by speaker—an important modulator of newsworthiness in the domain of fact checking.
If algorithms aren’t configurable, the outlets using those leads may end up with exclusivity issues, according to Staffan Mälstam at Radio Sweden, a beta tester for the Newsworthy tool. When every newsroom is getting the exact same leads from the default algorithm, speed becomes the only obvious competitive differentiator. “If we didn’t do this stuff immediately, other channels might, or local newspapers might have just printed those statistics so that it was no use for us,” Mälstam explains. More configurability would allow newsrooms to compete based on how they’ve set up the tool, including what sources to monitor, what definitions of newsworthiness to calculate, and what types of filters to apply.
ICYMI: Facebook and The Innovator’s Dilemma
Another problem is the sheer volume of leads computational story discovery tools can produce. The Tech & Check project sends 15 leads per day based on CNN transcripts, but these only translate into about one additional fact check per month at The Washington Post. That’s not a great conversion ratio. While the concentration of promising leads might be increased by improving the algorithm and allowing for greater configurability, an equally important factor is how much reporter attention is available to chase those leads. That varies with the news cycle.
Alert fatigue is a real danger. Mälstam suggests that getting one solid lead per month from Newsworthy might be fine—many more than that can become overwhelming. In order to turn a statistical lead into an interesting news package with local context and sourcing, “We have to put like one or two people to work with it [the lead] for one week,” he explains. Angie Holan, an editor at Politifact, says that it typically takes a reporter at her outlet a day or two to check a claim and prepare it for publication. Every algorithmic lead creates a variable amount of human work that depends on the required reporting depth. All of this underscores the need for newsrooms to be able to set the volume and type of leads they receive.
There’s also the question of how much journalists should trust leads generated by algorithms. In the Newsworthy lead shown above, there’s a link to the original data at the bottom of the lead. That’s by design, so that there’s transparency into the data the algorithm used to generate the lead. Leads from Tech & Check also include a link to the transcript of each check-worthy claim identified. This allows journalists to catch algorithms making mistakes, which can be a problem in Tech & Check’s quote attribution. Kessler recounted one salient mistake when the machine attributed several Sarah Sanders quotes to Bernie Sanders. But with one click to look at the transcript, he was able to spot the error. To move forward with a fact check, the original video of the claim on CNN also needs to be pulled to make sure the transcript is accurate. “We know these are automated tipsheets so we have to double-check them,” Holan explains. Many of the reporters I talked to indicated that they treated the automated news leads as any other source: worthy of skepticism.
It’s still early days in the history of computational story discovery. Experimental prototypes are already yielding results that lead to news stories, but these tools can be improved. They are, after all, just that: tools for human reporters.
Has America ever needed a media defender more than now? Help us by joining CJR today.



