

Executive Summary
Artificial intelligence tools have become much more powerful—and easier to use—over the past few years. They present substantial promise for building newsgathering tools to help reporters find stories in the vast quantities of data now being published online. Taking court reporting as a case study, I built a tool powered by a custom AI model using a technique called named-entity recognition to sort through court documents to help a reporter find potentially interesting search warrants that are worth reading—and potentially worth writing about. The bot sends a Slack message every hour with categorized search warrant documents for the reporter to consider researching. Key takeaways for journalists interested in embarking on similar projects include:
- Generating training data is a very iterative process as you adjust your goals, make mistakes, and account for the model’s blind spots. It takes far more time, effort, and attention than training the model.
- Generating training data requires someone with domain knowledge relating to the topic area of the project. You should either acquire that knowledge yourself, or get buy-in from a reporter to spend a few hours clicking buttons to classify the data you gather.
- It’s important to use product thinking to design the tool’s output to fit the reporter’s mental model. That is, your tool is not useful if the user can’t make sense of how you’ve chosen to organize the data. You can accomplish this by working with the reporter early and often.
- For newsgathering tools whose output will be checked by a human before publication, you don’t need to know the details of how your model architecture works, but it’s useful to understand the basics if things aren’t working as well as you’d hoped.
- However, you should get a deep understanding of how your metrics work and how they relate to your task. Fifty percent accuracy on a named-entity recognition task is quite good—and may be more than good enough—but 50 percent accuracy on document classification into two categories is pretty bad. See “Notes on Accuracy” for an example.
- Training and running costs are quite low, and you don’t need specialized hardware. Running costs are less than $100 a month, which could easily be lowered; in this case, training was done on Google Colab, which has a free tier and for which I used a $10-a-month paid tier. Ideally, this sort of purpose-specific AI-powered bot can make dealing with large or frequently updating document sets more tractable.
Artificial intelligence and natural language processing have soared to prominence in consumer products in the past few years, but are only beginning to be used in newsgathering. Many of the existing instances use off-the-shelf AI models in fairly simple ways, such as automatically categorizing ads as political or nonpolitical, or categorizing tweets as fact-checkable or not. These have often been fruitful, but the real power of such models comes in customizing them.
Large, frequently updated sets of documents are increasingly available online and are known to contain items that are newsworthy and interesting. However, in our ever-shrinking newsrooms, it is unlikely that any reporter has the time or inclination to read through all of them, every day.
Taking court reporting as a case study, the purpose of this project was to examine the extent to which it was possible to combine AI with journalistic judgment to automate the analysis of large, frequently updated data sets in order to surface only the documents of potential interest to reporters.
The resulting prototype solution tests the role of task-specific machine-learning models meant to assist with the specific newsgathering task by imitating judgments an indefatigable reporter would make. This prototype is one of the first uses of custom-trained named-entity recognition (NER) in a newsroom setting; a secondary goal of this project was to attempt to introduce this tool into the computer-assisted-reporting community.
An algorithmic approach for “news discovery” automates the process of identifying relevant documents. Other such projects in newsrooms have identified potentially relevant mentions of algorithms on government websites, proposed legislation, and automatically collected political advertisements. This project was created to help Justin Rohrlich, a reporter at the Daily Beast who frequently writes about the federal courts, including a controversial seizure of the contents of safe-deposit boxes operated by a man accused of running a vast criminal empire. At the top level, automated news discovery increases a reporter’s efficiency, accomplishing the same research in less time, but also helps find stories that otherwise wouldn’t be discovered due to how time-consuming manual searches can be.
Faced with a deluge of court filings, reporters sometimes find their decisions about what to read to be haphazard. “There’s no rhyme or reason why I would open one case or another,” Rohrlich says. Often the filings turn out to be boring or irrelevant. Rohrlich said he just paid an $800 quarterly bill from pacer, the federal courts’ public-access records system—and $775 was for stuff that was useless. So any ability to use AI to separate wheat from chaff saves both time and money.
In our case study, each weekday we narrowed down a set of 400 documents into 125 likely search warrants in 11 categories; usually a few documents a week are intriguing enough to pay for. (Each usually costs a dollar or two.)
Rohrlich says that “any way that you can narrow it down” is valuable. In that sense, the baseline for the AI model is zero—any way to hide chaff or highlight wheat is a win.
In this report, I’ll explain the background of why it’s worthwhile to run this experiment; the method in both technical and nontechnical terms; and the results, as well as a discussion about when to invest in projects like these, in terms of technical choices and tools. The primary audience for this report is data journalists and news organization leadership to help decide how and when to embark on projects using AI to assist in newsgathering.
Background and related work
The work of investigative news reporting relies on a variety of discrete tasks, including coming up with a hunch, finding sources, talking to those sources, researching documents, and assembling a narrative.
Some of these tasks are repetitive and time-consuming—but they can be automated!
As computer programming has been democratized, newsrooms also have sought to “automate the boring stuff” with data ingesters that gather frequently updated data, or with alerters to notify reporters about website changes. These sorts of tools tend to be fairly simple, transforming the format of data to be understood at a glance without making complex decisions based on its content. But that’s exactly what I predict will be the most fruitful area for AI-based automation: making content-based decisions about rows or documents within large datasets. However, relatively few newsgathering tasks have been automated in this manner—because even the boring tasks rely on skills that computers have only lately begun to learn, such as
- recognizing objects in photographs, e.g., guns in dashcam footage
- extracting the meaning of documents, e.g., the partisan lean of political ads
- sorting documents based on implicit taxonomies, as in this project.
Even the simplest, most boring tasks in a journalist’s workflow rely on an in-built understanding of the world and the context of the company, agency, or social context under investigation.
It’s important to note that the goal of this tool is not to draw a publishable conclusion about court documents. Such a conclusion (“This document is about the search of a vehicle”) would not only be journalistically uninteresting, but also trivially easy for a human to check by simply reading the document. This means that, while the accuracy of the tool is not 100 percent, it’s still good enough to be useful.
Glossary
The AI field is full of jargon. I’ve used some of that jargon in this report, but I want to pause first and define the terms for non-technical readers.
- model: a downloadable artifact that makes some sort of decision based on an input; the process of creating a model is called “training.”
- training data: examples of the kinds of decisions a model, once trained, is supposed to make. The training data take the form of an example input and the correct output.
- named-entity recognition (NER): a specific kind of AI task meant to pick words or phrases out of a longer sentence or paragraph.
- classifiers: a specific kind of AI task meant to take an input and output one of a handful of possible categories, like categorizing texts as true or false, Democrat or Republican; or categorizing dog images by the breed of dog.
- natural language processing: AI as applied to human languages
- computer vision: AI as applied to images
- neural networks: a dominant category of AI “architecture,” that is, a specific structure used by models
- bert: a popular natural language processing model
AI context
Until a few years ago, machine learning often had trouble with image and text data because patterns that were easily interpretable to humans—like the shape of a car, or a misspelled brand name of a phone, or a name—couldn’t be understood by computers.
Recently, a key breakthrough in machine learning has come through massive, pre-trained models that come with a baked-in (albeit imperfect, often biased, and easy to overstate) statistical “understanding” of the world that allows them to make certain human-like judgments. In intuitive terms, these models already know how to distinguish a dog from a car, or how to tell a person’s name from that of a corporation.
Previously, training a model to learn to distinguish among, say, cars was possible, but time-consuming and expensive—so training a model to deal with a broader domain of possible inputs (cars, dogs, scanned documents) was infeasible. With the evolution of highly generalizable pre-trained models like AlexNet (for images) or bert (for text), that has changed.
Pre-trained models are ready-to-use models provided by other developers who have taken on the heavy lift of using a large corpus of training data to build models that yield highly accurate results across numerous domains. As a result, developers of specialized tasks don’t have to create large datasets to build their models. Instead, they can rely on a pre-trained model, and, if necessary, improve their accuracy by fine-tuning it to suit a particular task. For example, bert has already been trained to know that an iPhone, a Samsung Galaxy, and a TracFone are similar to each other. So if we fine-tune the model to classify examples including “iPhone” or “TracFone” as members of the “phone” category, the model should be able to extrapolate that it should classify examples including the phrase “Samsung Galaxy” in the same way—even if the fine-tuning training data didn’t include any Samsung Galaxy examples.
This fine-tuning relies on manually labeling at most a few hundred examples specific to our task to generate training data. In essence, this process lets technologists ask a reporter to do just a small fraction of the boring stuff (generating the training data) and let the computer do the rest. One downside of this approach is that the “boring” reading of large quantities of documents might result in reporters getting a better implicit understanding of the subject matter and serendipitously finding newsworthy documents; my hope is that the training data generation process will allow for the first, while a sufficiently exhaustive search of the resulting documents allows for finding the right newsworthy needles in the haystack.
Newsroom AI context
Much recent journalistic AI work has focused on assisting reporters in newsgathering, according to a Knight Foundation report of which I was an author. Unlike in other domains (e.g., astronomy), practically every newsroom use of AI involves automatically making decisions that humans could make, but in a system where a simple decision has to be made so often or so quickly that a human would be unlikely to have the attention span. Many of those projects use classifiers—in essence, automatically sorting things into categories—to sort whole documents. However, a few use custom named-entity recognition models that extract portions of a document, e.g., to pull out a list of the kinds of “cars” that had been subject to a search warrant, like “1997 Dodge Ram,” “Grey Honda Accord XL WI License Plate ABC123,” and “2017 Chevrolet Cascade with Vin Number 12345.”
In the federal court system, this methodology can be applied to court documents to identify cases involving search warrants and the items being searched, or other such subcategories. It could also be used anywhere large sets of somewhat similar text are regularly published, such as accident, incident, or inspection reports from highly regulated industries like manufacturing and transportation, e.g., to pull out a verbatim description of the cause of a crash or the type of goods carried by a vehicle.
Legal AI context
Much of the legal AI development has focused on very different subject areas, like contract drafting or sentencing decisions.
- A group at Stanford and the University of Oregon has sought to extract information for transcripts of parole hearings. They have noted that long documents—common in the legal context, with affidavits for search warrants being the goal of this project—are difficult for modern NLP to understand.
- Commercial projects, like Litigation Analytics from WestLaw Edge, use a combination of machine-learning models, expert-written rules, and human review to perform tasks such as extracting information from dockets about who filed motions and which judge presides over a case, largely to produce analytics about lawyers, law firms, and judges. Like this problem, most filings fit a predictable template. That system uses rules to catch (with 100 percent accuracy) filings that fit the template, then machine learning only to deal with those that don’t fit.
- Other research using docket data has sought to link motions and rulings on those motions.
- Scales-OKN, a collaborative academic research project based at Northeastern University, has acquired a large quantity of data about the workings of entire district courts and created ontologies to map filings to events as understood by participants in the legal system. The project links documents that relate to the same event to generate analyses, like how long a particular process takes, how often a given motion is granted or denied, or how processes differ across districts.
- John Keefe has built a non–AI-powered court records alerter, Pacer Porpoise, that relies on the same pacer RSS feeds and alerts based on keywords.
Method
For newsrooms to set up a real-time—or near real-time—alert system to automatically identify documents of interest that require further investigation, they first need to create a model that mimics a reporter’s approach, identifying the steps a human would take, and codifying those as heuristics in the model.
How to choose heuristics to model1
This study is based on my own experience as a reporter and on an interview with a specialist document-oriented reporter, Justin Rohrlich of the Daily Beast. It assumes that when a reporter is faced with a large, routinely updated document set, they rely on a series of simple experientially derived heuristics to winnow down the data to a subset that is likely to contain newsworthy documents, which are then examined closely. The prototype aims to replace only the simple heuristics with AI, and still delivers potentially interesting documents to the specialist reporter for the final newsworthiness judgment.
For this case study, I sought to discover heuristics by asking an expert, Rohrlich, to describe his methods for finding newsworthy court documents, and then to walk through that process: both forward, by searching, and backward, telling the story of how he found documents he later wrote about. Speaking to beat reporters or subject matter experts prior to developing heuristics for any given project is key, because the goal (“interestingness”) isn’t directly teachable to an AI model. Because court data is generally public and because Rohrlich relies on it in his reporting, I seized that opportunity to create a pacer-focused AI tool as a means of experimenting with custom-trained AI models for newsgathering tools.
Rohrlich’s first heuristic within the set of all court documents is to look for search warrants. He often searches pacer using keywords like “search warrant” or “phone,” then buys and reads some of the results. While many court documents are boring disputes between businesses or procedural filings in criminal cases, a search warrant is often the first document filed in a case (so the underlying situation likely hasn’t already been reported by another outlet) and the affidavit portion of search warrant applications may contain enough intriguing details to make a story.
Within the set of search warrants, Rohrlich relied on his heuristics. He ignored certain filings based on the type of item searched. “Packages” are likely to be boring to him because they tend to be drug seizures; searches of vehicles in border districts like the Southern District of California tend to be searches for immigrants smuggled in traffickers’ vehicles. I programmed the AI system to use this kind of grouping as a heuristic because Rohrlich told me it was useful to him. (These heuristics are specific to Rohrlich’s beat; a reporter focusing on border patrol tactics or drug laws might be interested in what’s boring to Rohrlich.)
Rohrlich was able to explain his methods, but there may be other, better ways—like a lengthier ride-along with a beat reporter to see what kinds of implicit decisions they make on a day-to-day basis— to discover the heuristics that are in use.
It’s not yet clear to me whether these heuristics are reporter-specific. Would other court reporters find search warrants to be an especially fruitful source of story ideas? Would they find categorizing warrants by the item searched (and district court, and, implicitly, date) to be useful? I leave this question for further research.
Some AI for newsgathering tools have taken a larger focus than that modeled here. Dataminr, for instance, attempts to model when a tweet is trustworthy and newsworthy. Spangher et al. have trained a model to estimate the newsworthiness of documents, even those of kinds the model hadn’t seen before. Nick Diakopoulos raised the interesting question of whether my experiment had an especially narrow focus, relative to other uses of AI in newsrooms. It may well be—which raises questions of whether the cost of teaching fine-grained heuristics (versus a more general heuristic, or using off-the-shelf machine-learning APIs) is worth the cost outside an experimental context.
Off-the-shelf machine-learning APIs such as those offered by Google Cloud, Microsoft Azure, and Amazon Web Services can, for instance, recognize people’s names versus those of organizations. For some projects, that may be good enough—and it’s far simpler than training your own model.
However, the heuristics described by Rohrlich—and other reporters, in other contexts—cannot be modeled by current state-of-the-art machine-learning tools. For instance, often what makes a case newsworthy are ties to recent newsworthy events, such as an extensive public interest in the people who stormed the US Capitol on January 6, 2021. While ongoing research seeks to make pre-trained AI models better aware of changing temporal context, it’s not currently doable with off-the-shelf methods.
Building a pipeline
One way to think of the role of the AI system is as a two-step process: first, finding potentially interesting documents, and, second, surfacing them for the reporter to decide whether they’re truly interesting, and thus worthy of further reporting or research.
With this goal, one might be tempted to try to teach the computer to apply heuristics for what makes a document relevant or interesting, but such heuristics are slippery to define in English—let alone to operationalize in code. Perhaps it’s better to find those documents that are definitely uninteresting, so that the reporter can ignore them. This might be a better way to think of the problem: What’s interesting is frequently hard to define, while known classes of uninteresting documents are often almost obvious and can be flagged accordingly.
For instance, Rohrlich says searched packages are usually uninteresting as they’re mostly cases of drugs sent through the mail. What makes a searched object interesting is harder to define: safe deposit boxes, online accounts, and animals might be interesting, though it’s hard to come up with a specific list in the abstract.
Whether an AI system works thus depends on two factors: whether the expert’s heuristics really work in the abstract, and how well the model has learned to imitate the heuristics.
Because the model will never be perfect, you will have to decide, from a product perspective, whether the objective is to minimize false positives (so reporters aren’t inundated with manual work) or false negatives (which means important documents can slip through the cracks).
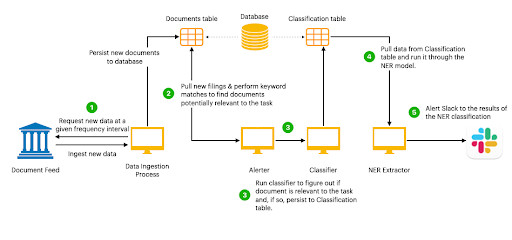
Figure 1: NER Pipeline
There is no single optimal technology solution for this workflow. Depending on how newsrooms are set up, they might opt for different cloud services, programming languages, and even machine learning libraries. In the next section, I will describe how I used the following tools to pull data from pacer, a system used by the federal court system to publish documents, and extract relevant data for filings that contained search warrants.
In our case, to build a system that alerts the reporter to an “interesting” court document about search warrants, a real-time pipeline needs to be set up that ingests, codifies, and classifies the documents, and then alerts reporters about documents of interest.
Figure 1 illustrates the end-to-end workflow, which is composed of:
- A data ingestion system that pulls in new records at predefined intervals and stores them in a database table.
- An alert system that polls the database table for new filings that match a set of predetermined criteria like keywords, timestamps, or metadata, and surfaces that to the classifier.
- A classification system that ingests the surfaced document to verify whether the document is of interest to the newsroom. The results can be stored in a second database table.
- A named-entity recognition extractor that takes the relevant documents from the second table and extracts the items of interest, in essence, extracting metadata. This makes it easy for reporters to evaluate similar documents at the same time.
Reporters are then notified of the documents of interest via several mechanisms, including Slack or e-mail.
Labeling training data
To train the named-entity recognition model—more precisely, to fine-tune the pre-trained model and create a new model whose job was to pull out and classify the objects listed in search warrants to be searched—I ended up hand-classifying 1,369 examples into 10 categories.
As I started the project, I didn’t know how many examples I would need—or how many categories I would want. I had to refine both in an iterative process of experimenting, seeing what worked and what didn’t, and then repeating.
From talking to Rohrich, I knew some logical categories, like packages, cars, and phones. To find more, I read through a few hundred examples in a spreadsheet and categorized them by hand, creating new categories as needed. Then I created a pivot table (Figure 2) to find which were most and least common, and adjusted some of the less common ones (e.g., creating an “electronic devices other than phones” category to span computers, thumb drives, and car entertainment systems).
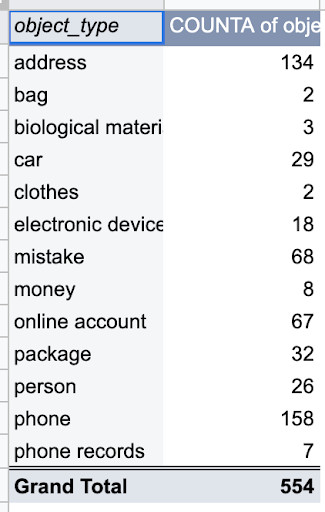
Figure 2: In this pivot table, “clothes” and “bags” have very few examples, and are conceptually similar, so they might bear to be combined into a single category.
Once I had created a list of categories, I began labeling examples for real. The examples I picked were chosen arbitrarily from among those classified as search warrant documents. The point is to mimic as closely as possible the distribution of the examples the system will be asked to classify once it is in production.
I labeled a smaller number of examples, trained a model, and examined its performance by looking at accuracy metrics, and then looking at examples and judging whether the result was right, egregiously wrong, or acceptably wrong.
The first model was good, but not good enough. I took three steps to try to find blind spots and improve performance.
- Examining uncommon classes: Overall performance was good, but this obscured a disparity between common classes and uncommon ones. For more common classes (e.g., phones and addresses) performance was very good, but for uncommon classes (e.g., cars and electronic devices other than phones) performance wasn’t as good as I wanted. This made sense: the model had fewer examples to learn from.
- Compiling a small list of known interesting documents, and ensuring the model does well enough on those examples to be useful.
- Looking through the model’s mistakes for three possible errors:
I continued this process iteratively several times until the performance rose to a level I thought would be good enough, but there’s no magic number. More training data means better performance; less means worse. What level of performance is good enough depends on the users and use case.
A Case Study: pacer
Because court data is generally public, and because Rohrlich relies on it in his reporting, I took the opportunity to create a pacer-focused AI tool as a means of experimenting with custom-trained AI models for newsgathering tools. This section of the report focuses on the project-specific details of pacer and court documents.
pacer context
Court documents are frequent topics of news reporting—for accountability stories about what the government is doing in our names, for spot news stories about crime, and for fun stories about weird, clever, or stupid criminals. The upside of these stories in the US context is that the workings of the courts are generally public, at least in theory, and reporting on the courts is protected against libel lawsuits by the near-impenetrable legal shield of the fair-report privilege. Part of the challenge, however, is that huge numbers of documents are filed in court each day—and most of those documents are boring.
Additionally, what documents are practically available to the public differs among various state trial courts and between federal district courts; some courts publish nothing at all online ( North Carolina), some charge high prices for documents posted online (Los Angeles County, California), while others publish everything within certain case types for free (New York State).
The federal court system publishes documents on a system called pacer, which makes almost every document available; however, it charges 10 cents per page, up to a cap of $3 per document. Just as crucially, it charges 10 cents per “page,” up to $3, for dockets, which list the available documents per case. Without buying a full document, it’s difficult to know what it concerns. Titles are often vague and metadata is often missing or incorrect, even for documents that match a search query.
Finally, pacer charges an uncapped 10 cents per page for listings of recent filings (docket activity reports)—which, if purchased daily for the entire US court system, could easily cost hundreds of dollars. Commercial systems likely use this data, but free compilations of court documents like the Free Law Project’s CourtListener project don’t gather it. Luckily, many of the courts publish RSS feeds of certain types of filings, which this project uses as its source material.
The specific task solved here—a bot to identify and categorize search warrant documents—is meant to be an example to which other newsroom developers and data journalists can analogize their tasks. It relies on using the abovementioned RSS feeds, and implementing the heuristics a specific reporter uses when he manually searches for potentially newsworthy court filings.
The end-to-end workflow I created to accomplish this is based on the pipeline described above: it consists of five steps, it runs hourly, and it connects to the RSS feeds of the court filings.
- Every hour, the data ingestion system visits each RSS feed and records new filings in a database.
- The alerter system searches the database for any new filings that match keywords that indicate a possible search warrant.
- The alerter runs those filings’ case titles (e.g., “USA vs. One Black iPhone”) and document type (“Application and Affidavit for Search Warrant”) through the search-warrant-or-not classifier model and records the results to a classification results table.
- The alerter takes the filings listed in the table as being search warrants and runs their case title and document type through the named-entity recognition model to extract and classify the searched object (e.g., the searched object is “iPhone,” which is a kind of “phone”).
- The alerter sorts the filings by category and court and sends alerts via Slack.
The technology used in the prototype is a transformer-based neural network, trained with data gathered specifically for this task. Neural networks are a subtype of machine learning, which is in turn a subtype of artificial intelligence; in broad terms, neural networks automatically draw conclusions about how to react to unseen examples when trained with a set of examples that are labeled with the developer’s desired reaction.
Technical/Implementation Details
The outcome of the project was a qualified success. The bot works very well, and Rohrlich continues to use it. Its success is limited, because the federal courts make less data available than expected; for only 15 out of 94 federal courts was the tool able to identify more than 10 search warrants over a month-long period, and many of those warrants were sealed.
Building the prototype tool
The aim of this methodology is primarily to provide a recipe to be loosely followed, and secondarily, to be an approximate recounting of the steps I took.
There are separate sections for the specific tech tools used and for the training data generation.
- My first step was to find a few heuristics to train a computer to imitate, within the context of court documents. By talking with Rohrlich, I learned that he frequently seeks out search warrants, having found that those often include a detail-rich narrative portion that can be transformed into a news story. (See “How to discover heuristics to model”↩ above.)
- Within the set of search warrant documents, Rohrlich uses additional subcategorizations that I am considering seeking to instrumentalize:
- Some categories of alleged crimes don’t make good news stories, like search warrants related to gun trafficking, drug trafficking, child sexual abuse material, and immigration offenses. However, these categories can’t be easily ascertained from published records.
- The district court in which the search warrant has been filed (which corresponds to the region where the alleged crime took place). Rohrlich says he tends to ignore some search warrants from districts along the US-Mexico border, having found that they frequently are for immigration-related allegations.
- The object to be searched, like a phone, a house, or a package. In Rohrlich’s experience, the packages are all boring. “Just people sending drugs through the mail,” he says.
- Whether the full court documents are sealed or not.
- Next, I needed to gather the available data. I wrote a Python ingestion script to gather data and write it to a database. The data looks like this:

and the scraper is here.
4. To imitate those heuristics, I gathered training data—basically, a few hundred results from the RSS feeds that I hand-labeled with the “right” answer. See the Training Data Generation section below for even more detail.↩
- First, for a given RSS entry for a newly filed document: is it a search warrant or not? In a spreadsheet, I labeled this data in a column saying True or False. This is more complicated to determine than it sounds—which is why it was a good candidate for machine learning. Different courts give search warrant cases different sorts of names, from “USA v. iPhone – tie dye colored case” to “USA v. Sealed” to “In the Matter of the Search of The Digital Device Assigned Call Number 714-XXX-XXXX and Subscribed to XXXXX XXXXX.” (Redactions mine.) This makes it hard to write rules that find all the search warrants. There are also many court documents that involve wrangling about search warrants, but which aren’t warrants themselves—so we want to exclude those.
- Second, for RSS entries for documents that are search warrants, what’s the thing being searched? I labeled these first with Prodigy (paid software associated with SpaCY), then with Label Studio (free software). The labeling components of both worked well, but Label Studio was more flexible in exporting to common NER data formats, whereas Prodigy required writing a small glue script to convert between formats. Therefore I’d recommend Label Studio.
- The sealed-or-not heuristic I have not implemented, but I believe it would be useful future work.
- The categories-of-crime heuristic does not appear to be doable with free data. A future project that purchased each document could likely learn to extract the type of crime charged, either from semi-structured text listing a US code section or from free text describing the charges.
5. Model training:
- I used bert for the search-warrant-or-not classifier. I had intended to try several architectures, including base berts with concatenated case title and document type, base bert with separate berts for case title and document type, and Legalbert. However, the first model performed so well (>99 percent accuracy) that I was unable to effectively compare the subsequent models. Colab Notebook.
- I used flair for the named-entity recognition portion—that is, identifying the kinds of objects named in the search warrant document. I also evaluated spaCy 2.0, which did very poorly, scoring about 30 percent, albeit with a somewhat smaller training set. I suspect this was because its CNN-based architecture was less capable of evaluating the entire length of the case title than flair’s transformer architecture. (During the course of this research, spaCy 3.0 was released, with a transformer architecture that was competitive with flair and would make a good option.) See the Results section for more detail on metrics. Colab Notebook.
6. Design of the Slack bot: All documents ingested in the past hour are classified as search warrant or not, then any searched objects are extracted and classified by the NER step into 12 categories. Then documents within each category are alerted to Slack, with the case title, document type, and a link to download the documents, categorized by district court. The aim of this design is to be easy to scan for cases of interest.
- Unfortunately, many cases don’t include a searched object: for instance, those titled “USA v. Search Warrant.” For these, it’s hard to get any free information for whether the case might be interesting. These cases are included in a grab-bag category of unrecognized items, sometimes along with rarer objects the NER couldn’t categorize. Rohrlich said it’s better to present this, so that the tool is exhaustive, than to hide them.
7. Iteration: The designs of the Slack bot and the training data were created, tested, and then revisited.
- Training data: In particular, the biggest gain in model performance came not from adding training data (though it helped), but from fixing mistakes or inconsistencies in the training data. As a side effect of the advances in machine learning that make it possible to train a model with a few hundred labeled data points, mistakes can confuse the computer, since there are relatively few correctly labeled data points to cancel out the mistake.
- Design: AI-based projects are no exception to the rule of newsroom software design, that the end-user has to be involved. For instance, Rohrlich asked that the Slack bot’s design imitate that of Pacer Porpoise in categorizing items within the object categories by district court. And regarding search warrants for packages, Rohrlich noted that they’re usually boring, “but worth having in there—ya never know.”
Training Data Generation2
Training data for the pacer case study is available on GitHub.
Classifier: (Search warrant or not)
I used Google Sheets to categorize 4,113 non-search warrant examples and 671 search warrant examples.
That sounds like a lot, but I categorized a lot of these in a very easy way: with a keyword search. Then I scanned them to make sure the keyword search hadn’t misbehaved—which was a lot easier than typing False into Google Sheets 4,113 times! It’s important to include negative examples—things that aren’t search warrants—so the model has an idea of the diversity of things it should ignore.
Those examples were divided into 3,690 training examples, 411 validation examples, and 274 test examples.
Named-entity recognition (searched-object extraction and classification):
Corpus: 1,369 sentences, divided into 1,065 training + 151 validation + 153 test sentences.
These were labeled with LabelStudio, free software with a web-browser interface.
LabelStudio looks like this:
The CONLL format used for the training data looks like this:

Tools Used:
Classification (“is this a search warrant or not?”):
- bert, for model architecture
- Google Colab, for model training
- Google Sheets, for data labeling
Named entity recognition (“what thing was searched?”):
- flair, named-entity recognition library
- Google Colab, for model training
- Label Studio, for data labeling
Alerting:
- Slack
- AWS Lambda
Resources
- Training data, pacer scraper, and alerter: https://github.com/jeremybmerrill/pacerai/
- Classifier training: https://colab.research.google.com/drive/16l_Fr9d9oLrGPz7cQwtD5Z3sJGsHQagD?usp=sharing
- Named-entity recognition training: https://colab.research.google.com/drive/1bK5lsugjEX6X4QdGFmeA4KglUPQaRuPh?usp=sharing
Notes on Accuracy
The extremely high accuracy rate for this classifier made it difficult to evaluate other approaches such as separate bert models for the case name and document title, with the resulting vectors concatenated before classification. Hand-coding additional test data would help distinguish the two, but if simpler methods work adequately there may be no need to use more complex ones.
The NER’s accuracy rate was 100 percent for objects it identified (i.e., no false positives). False negative rate was 20 percent, for which the NER model made no guesses at all—though these were still provided to the reporter to read, just in a less organized way. Micro F1-score, a standard metric of NER accuracy, was 64 percent—though this score doesn’t perfectly line up with our intuitions about success, because it puts a focus on extracting the correct tokens representing the searched object “Black Motorola” from a longer string like “USA v. Black Motorola With no other identifying numbers or features Seized as FP&F No. 2021250300093101-0004 Application and Affidavit for Warrant,” which wasn’t crucial to this application. (“Black Motorola with no other identifying numbers or features” would be equally correct.)
One limitation to the success of this tool is that data is less available than I assumed at the start. Specifically, of the 94 US district courts, 74 have RSS feeds. Of those with an RSS feed, only 44 published a search warrant between June 24 and July 23, 2021. The Eastern District of Missouri published the most, with 434, while nineteen districts published fewer than five in a month, suggesting that these districts may not publish all search warrants via their RSS feeds. This apparent absence of some search warrants was an unexpected hurdle to this project, which future research should address by purchasing a few days’ worth of recent filings for each court to better quantify how many search warrants are filed in federal court each day. (Some law databases like WestLaw and LexisNexis have collections of substantially all dockets, but access to those can be very expensive.)
From the RSS feeds, we gathered an average of 33,519 filings per day, from which we identified an average of 70 search warrants, including documents filed earlier that had been recently unsealed.
Future Enhancements and Research Directions for Court Documents
Our overarching goal as journalists who cover the courts is to inform the public of what the government is up to. One big hurdle is that full filings are both expensive to purchase and time-consuming to read.
Rohrlich told me, “You just have to dig through the cases and see what’s what. That’s the most time-consuming part. If there was some way to be able to analyze the text in those filings…” Advances in natural-language processing that apply to long documents will help, but only policy fixes will address the cost issue. “I just paid a $1,400 pacer bill, [which] drives me insane. I imagine $50 I actually spent on worthwhile cases,” he said.
Within the smaller context of identifying document to purchase (and read “by hand”), here are two further enhancements:
- to identify which cases have been sealed (likely doable with rules and by linking data from multiple filings to create a deeper understanding of cases, instead of the current, simple filing-based representation)
- to prototype an extension to the tool, allowing it to purchase and parse listings of newly filed documents, thus covering courts that don’t publish search warrants via RSS. Since this could cost up to $10 per day per court, it may be worthwhile to limit it to courts that frequently have newsworthy cases, like the District of Columbia, the Eastern District of Virginia, and the Southern and Eastern Districts of New York.
Another easy possible extension would be to create a reporter-facing interface to write rules about how to handle categories of cases, e.g., “Don’t alert any search warrants that are detected to be in the PHONE category in the Southern District of California,” if that’s a heuristic the reporter already uses.
Final Observations
Assessing How Well the Prototype Works
It’s difficult to assess whether the prototype has been successful in increasing Rohrlich’s ability to cover the courts in a systematic way. It has, however, found documents that Rohrlich later wrote about: “Co-Owner of Shady Beverly Hills Vault Business Accused of ‘Extensive’ Criminal Empire.”
The component goals of finding a set of heuristics and implementing them in code using AI have been accomplished. The “is this a search warrant or not?” classifier achieved an accuracy of 99.5 percent, compared to a baseline classifier or looking for the word “search” in the document description, which achieved an accuracy of 95.7 percent using an off-the-shelf base bert model that classified documents based on the case name and document title concatenated into one string.
How much does a project like this cost?
The cost of training machine-learning models can be a source of anxiety for newsrooms. The total cost for computing resources for this project was under $200. The models were trained on Google Colab (which has a free tier); data ingestion was done with AWS Lambda (which has a free tier); analysis and inference was on AWS EC2 instances, which had an ongoing cost of around $50 a month.
That cost pales in comparison with the amount of money newsrooms may already be spending keeping tabs on local federal courts.
References
- Administrative Office of the United States Courts. (1988) Public Access to Court Electronic Records. [Online] Available at pacer.gov. (Accessed June 23, 2021)
- Bell, K., Hong, J., McKeown, N., and Voss, C. (2021) The Recon Approach: A New Direction for Machine Learning in Criminal Law. Berkeley Technology Law Journal, Vol. 37. Available at https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3834710
- Branting, L.K. (2017) Automating Judicial Document Analysis [Conference paper]. ASAIL 2017, London, UK. http://ceur-ws.org/Vol-2143/paper2.pdf
- Devlin, J., Chang, M., Lee, K., and Toutanova, K. (2018) bert: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of NAACL-HLT 2019, pages 4171–4186. Minneapolis, Minnesota, June 2 – June 7, 2019. https://aclanthology.org/N19-1423.pdf
- Diakopoulos, N. (2020): Computational News Discovery: Towards Design Considerations for Editorial Orientation Algorithms in Journalism, Digital Journalism. Accessed June 14, 2021. http://www.nickdiakopoulos.com/wp-content/uploads/2020/03/Comp-News-Discovery.pdf
- Lissner, M. (2010) CourtListener [Online] Available at: https://www.courtlistener.com/recap/ (Accessed April 21, 2021)
- Keefe, J. (2019) “Pacer Porpoise.”
- Keefe, J., Zhou, Y. and Merrill, J. (2021) “The present and potential of AI in journalism.” The Knight Foundation. [Online] Available at: https://knightfoundation.org/articles/the-present-and-potential-of-ai-in-journalism/
- Krizhevsky, A., Sutskever, I., and Hinton, G.E. (2012) ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems 25. https://dl.acm.org/doi/pdf/10.1145/3065386
- Northcutt, C.G., Athalye, A., and Mueller, J. Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks. [Conference paper]. ICLR 2021 RobustML and Weakly Supervised Learning Workshops; NeurIPS 2020 Workshop on Dataset Curation and Security. Available at https://arxiv.org/abs/2103.14749
- Rohrlich, J. and Melendez, P. (2020) “A Missile Engineer’s ‘Dark Fantasy’ and Alleged Revenge Plot.” The Daily Beast. [Online] Accessed December 9, 2020. Available at https://www.thedailybeast.com/former-raytheon-missile-engineer-james-robert-schweitzer-accused-of-leaking-classified-info
- Rohrlich, J. (2021) “Co-Owner of Shady Beverly Hills Vault Business Accused of ‘Extensive’ Criminal Empire.” The Daily Beast. [Online] Accessed July 26, 2021. Available at https://www.thedailybeast.com/co-owner-of-shady-beverly-hills-business-us-private-vaults-had-extensive-criminal-empire-feds-allege
- Spanger, A., Peng, N., May, J. and Ferrara, E. (2021). Modeling “Newsworthiness” for Lead-Generation Across Corpora. [Online]. Accessed October 29, 2021. Available at https://arxiv.org/pdf/2104.09653.pdf
- Sweigart, A. (2019) Automate the Boring Stuff. San Francisco: No Starch Press. https://automatetheboringstuff.com
- Systematic Content Analysis of Litigation EventS Open Knowledge Network. (2019) https://scales-okn.org/
- Trielli, D., Stark, J., and Diakopoulos, N. (2017) Algorithm Tips: A Resource for
- Algorithmic Accountability in Government. [Online]. Accessed January 17, 2022. Available at http://www.nickdiakopoulos.com/wp-content/uploads/2011/07/AlgorithmTipsTrielliStarkDiakopoulos.pdf.
- Vacek, T., Song, D., Molina-Salgado, H., Teo, R., Cowling, C., and Schilder, F. (2019) Litigation Analytics: Extracting and querying motions and orders from US federal courts. Proceedings of NAACL-HLT 2019: Demonstrations, pages 116–121. Minneapolis, Minnesota, June 2 – June 7, 2019. https://aclanthology.org/N19-4020.pdf
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez A.N., Kaiser, L., Polosukhin, I. (2017) “Attention Is All You Need.” 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA. Accessed April 30, 2021 https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
Has America ever needed a media defender more than now? Help us by joining CJR today.