

Sign up for the daily CJR newsletter.
Mark Zuckerberg, Facebook’s CEO, has been back in Congress this week to talk about the need to reform how social-media platforms moderate content—a realm within which Facebook is trying to establish a “best in class” reputation. New research from the Tow Center shows that the platform is falling short.
In order to understand how consistently and swiftly Facebook applies fact-checks to its namesake platform and Instagram, the Tow Center reviewed fact-checking labels assigned by the company to posts between October 1 and 5—the period spanning President Donald Trump’s COVID-19 diagnosis to his release from Walter Reed Military Hospital following three nights of observation and treatment. During that time, speculation about Trump’s condition dominated a news cycle already stretched by coverage of the ongoing pandemic, the upcoming Presidential election, and claims of voter fraud pushed by the Trump administration. In the absence of reliable information, rumors and conspiracy theories flooded social media; they included claims that “doomsday planes” had launched in order to ward off geopolitical enemies, and that Trump’s diagnosis was actually a “con job.”
Our review of fact-checking labels on Facebook during this five-day period found that the company failed to consistently label content flagged by its own third-party partners. Facebook’s ten US fact-checking partners debunked over seventy claims. We identified over 1,100 posts across Facebook and Instagram containing the debunked falsehoods; less than 50 percent bore fact-checking labels, even in instances where there were minor deviations from the original vetted posts.
Fact-checking isn’t the panacea to the large-scale problems of misinformation on Facebook. However, the social-media giant has touted its efforts with fact-checking partners since its Third-Party Fact-Checking Program launched in 2016. At the time, critics saw the initiative as a public relations effort to combat the narrative that rampant misinformation on the platform helped swing the election for Trump. “I don’t think their fact-checking has been any more than very cheap, very cut-rate public relations,” says Brooke Binkowski, a former managing editor at Snopes who was involved in the inception of the site’s fact-checking partnership with Facebook. (Binkowski is currently the managing editor at the fact-checking site TruthOrFiction.com.) In February, a Popular Information article about the scope and impact of the program found that “a majority of fact-checks were conducted far too slowly to make a difference,” as information can reach millions of people in a matter of hours.
Facebook continues to tout its use of artificial intelligence to automate fact-checking across “thousands or millions of copies” of similar posts spreading the same piece of information, thereby enabling their fact-checkers to focus on “new instances of misinformation rather than near-identical variations of content they’ve already seen.”
Our analysis found that Facebook still struggles to recognize similar content at scale. For example, we found 23 instances of a meme that attributed the murder of a Black Chicago teenager to “other Black kids.” Although an October 2 fact-check by the Associated Press found that the murder investigation in question was still open, Facebook was unable to recognize other iterations of the meme using similarity-matching algorithms that rely on natural language processing and computer vision.

Figure 1: A Facebook meme that we found 23 instances of; only two were fact-checked. The images are remarkably similar, with two major differences: The fact-checked images have a white border on the right-hand side, and some examples of the non-fact-checked images attribute the source of the meme to a subreddit.
As part of a recent year-long study on Facebook’s review system, Avaaz, a US-based non-profit that promotes international activism online, highlighted how misinformation peddlers can make minor tweaks to evade Facebook’s algorithms. This allows malicious pages to slip under Facebook’s radar or avoid attaining “repeat offender” status.
For a platform the size of Facebook, the economies of automation are critical. Currently, the inconsistent manner in which similar pieces of misinformation are algorithmically identified and labelled leave a lot to be desired.
So does the automation around Facebook’s new Voting Information Center, which the company promised users would be directed to when discussing voting on the platform. Based on our dataset, we found that the company failed to do this about 90 percent of the time.
When reached for comment, a Facebook spokesperson said, “If one of our independent fact-checking partners determines a piece of content contains misinformation, we use technology to identify near-identical versions across Facebook and Instagram.” However, they did not provide additional explanations for the multiple instances of inconsistencies Tow provided to them.
In 2018 , Mike Ananny, a USC Annenberg professor of communications, reported on the state of Facebook’s fact-checking partnership for the Tow Center. At the time, Facebook focused solely on identifying links to false claims and had yet to expand their fact-checking program to individual posts, memes, and videos. Facebook provided access to a queue of suspect links and dubious posts to fact-checkers at partner organizations; the posts in this queue were identified by user-flagging and a series of algorithmic inputs which Facebook did not disclose even to their own fact-checkers. Ananny found fact-checkers were frustrated by Facebook’s clumsy handling of similar content on both sides of the fact-checking process. “[Fact-checkers] didn’t have the ability to say, ‘Here’s a class of things; these look similar,’” Ananny said in a recent interview, which meant they had to add a link to each debunked claim on individual items one by one. On the other side of the queue, the fact-check was supposed to propagate through to identical and similar content algorithmically. Based on our conversations with multiple fact-checking partners, today, the process remains largely similar, but the scope of fact-checking now includes the whole gamut of content: links, posts, memes, and videos.
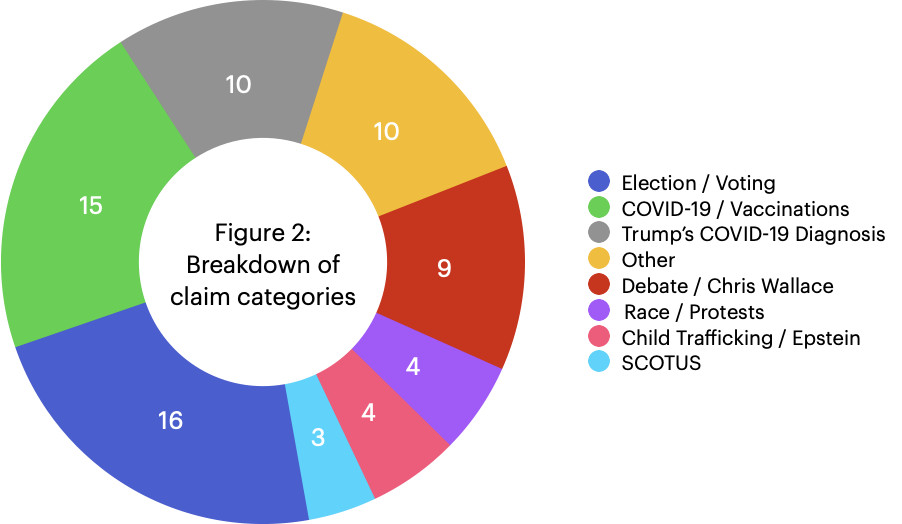
In the five-day period that we looked at, we found fact-checkers had debunked ten claims related to the President’s diagnosis, fifteen claims related to COVID-19 and vaccinations in general, and sixteen claims related to the election and voting (including claims about former Vice President Joe Biden). “Other”—the catch-all bucket—includes myriad claims, from false earthquake alerts to George Soros being banned from six countries. Figure 2 illustrates the classification of claims our analysis covered. We provide details on all the claims, the searches we ran, and our overall methodology below.
Trump’s COVID-19 Diagnosis
The top three claims in our dataset include “The Simpsons” allegedly airing a scene with the President in a coffin (51 posts), Trump boarding Marine 1 with a portable oxygen concentrator (41 posts) and a viral tweet “prediction” from September that Trump’s October Surprise would announce an infection and a swift recovery (32 posts).
In all three cases, we found Facebook still struggles to identify duplicate and near-duplicate posts, whether they are identical posts from the same user across Facebook and Instagram (Figure 3.1), posts containing the same images, or posts containing links to or screenshots of the tweet identified as the origin of the claim. Overall, we found that, of the 41 posts espousing the claim that “Trump boarded Marine One with a portable oxygen concentrator,” 65 percent didn’t have any labels on October 10, when we first looked at this post, despite the first debunking having occurred on October 4. All the posts contained either the same annotated images, screenshots of the original tweet, or the text from the original fact-checked tweet. A week later, three of the posts present in our dataset were unavailable (meaning either they had been deleted or their privacy settings had changed), but 27 posts remained up with no labels. Of these 27, three had a fact-check initially, but when the tweet they linked to was deleted, the cached version of the tweet continued to show the same text (Figure 3.2). Facebook’s “false information” overlay was removed, but related articles by fact-checkers were still visible. In this example, two of the three related articles suggested by Facebook have nothing to do with the claim (see Figure 3.2).
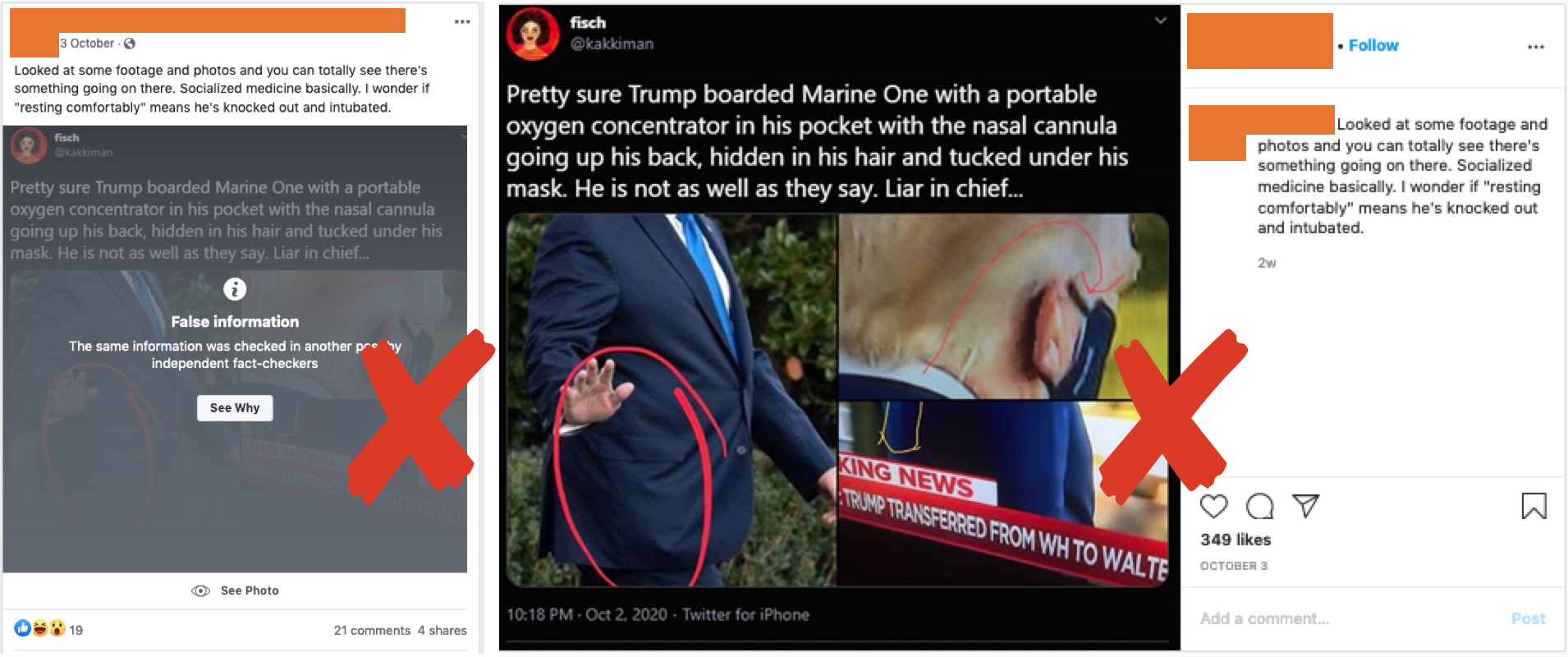
Figure 3.1: Two screenshots of the same post on Facebook (left) and Instagram (right) by the same user where only the Facebook post is fact-checked. We’ve removed identifying details from this image.
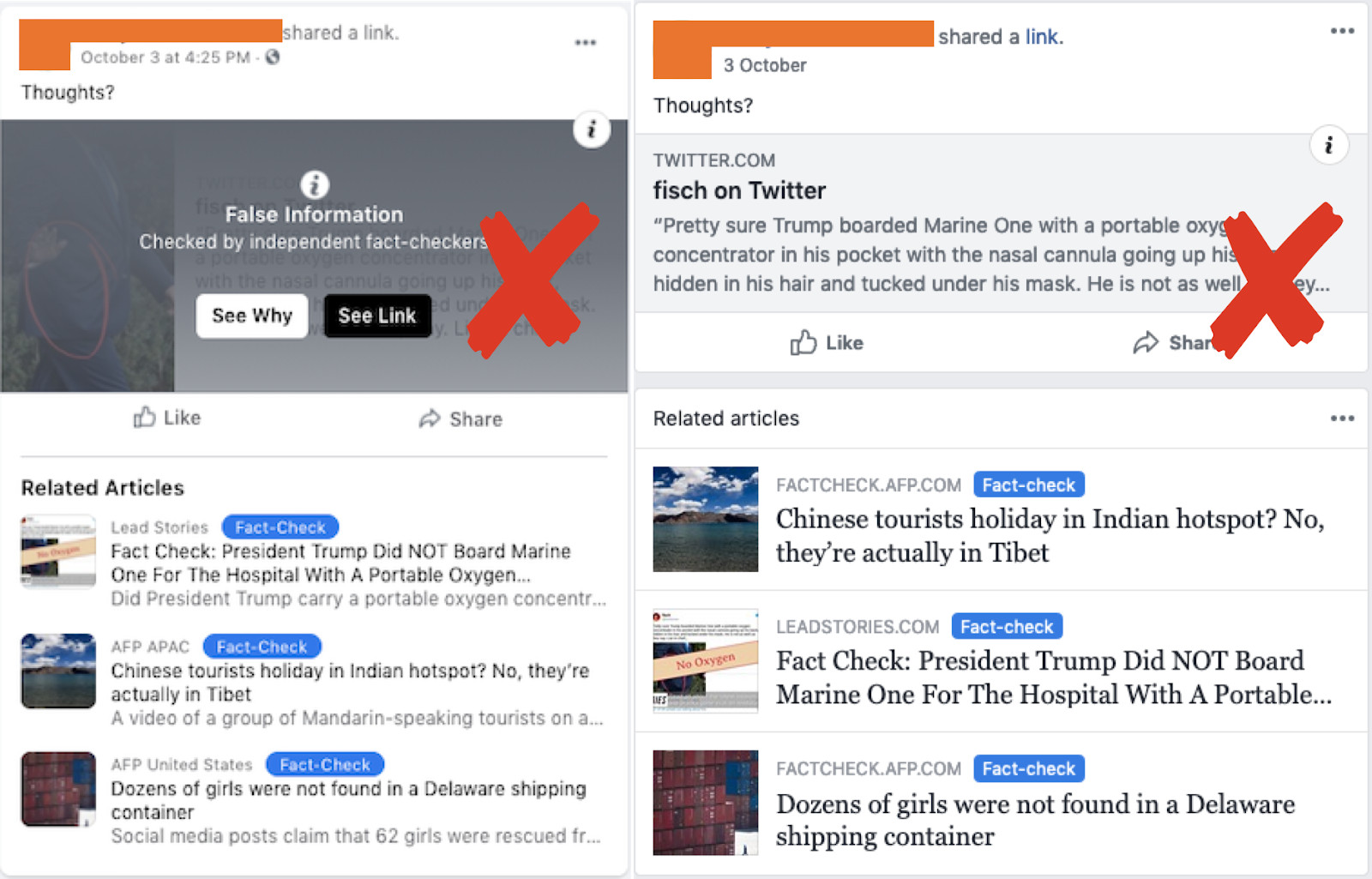
Figure 3.2: Two screenshots of the same tweet. The one on the left was taken on October 9, and the one on the right was taken on October 17, after the tweet was deleted. The fact-check layover disappears after the tweet was deleted, but the cached version of the tweet is shown to the user.
Facebook’s caching problem extends beyond just tweets. In a different example, a Washington Times story fact-checked by Lead Stories (an official Facebook US fact-checking partner) about Biden was updated with a correction, and the headline on the original story changed. However, multiple posts with the old false headline continued to circulate on Facebook (Figure 3.3).
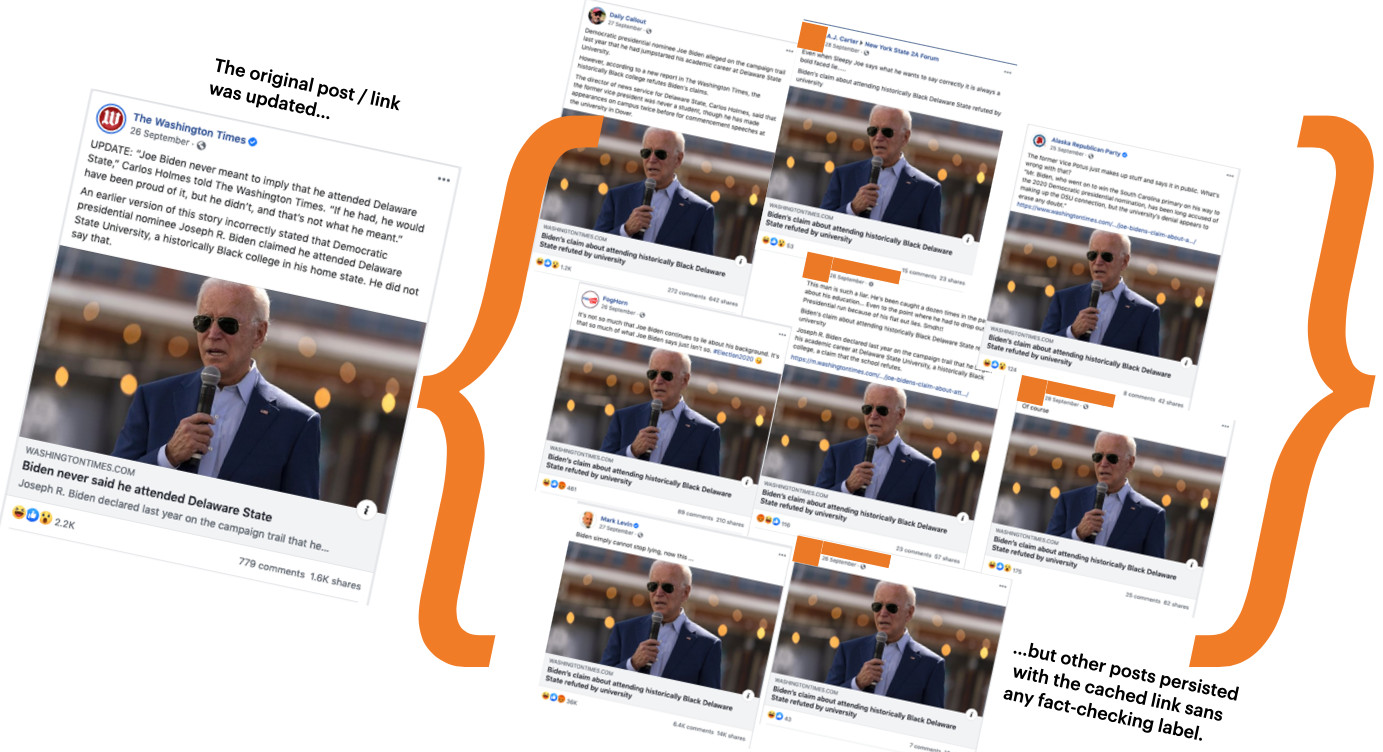
Figure 3.3: The original Washington Times story was updated as per the screenshot on the left. But other posts with the same link continued to show the old headline; none were fact-checked.
Of the 51 posts we found about the nonexistent “Simpsons” scene, more than 60 percent didn’t have a fact-checking label; most of those were either images or screenshots of the same original post. In May, Facebook boasted of their new AI system, SimSearchNet, that was built specifically to detect near-exact duplicate images. In this case, we found that an image with an added sticker, a screenshot of a tweet, and a cropped version of the original image resulted in missing fact-check labels.
Election 2020 and the Voting Information Center
In a June Facebook post, Zuckerberg announced the Voting Information Center, a hub for US voters to access election information. A label would be applied to all posts about voting directing users to the new hub. Zuckerberg clarified, “[t]his isn’t a judgment of whether the posts themselves are accurate, but we want people to have access to authoritative information either way.”
Out of the 105 posts we found pushing six debunked claims about mail-in ballots and election fraud, a mere twelve had a link to the Voter Information Center (Figure 4).
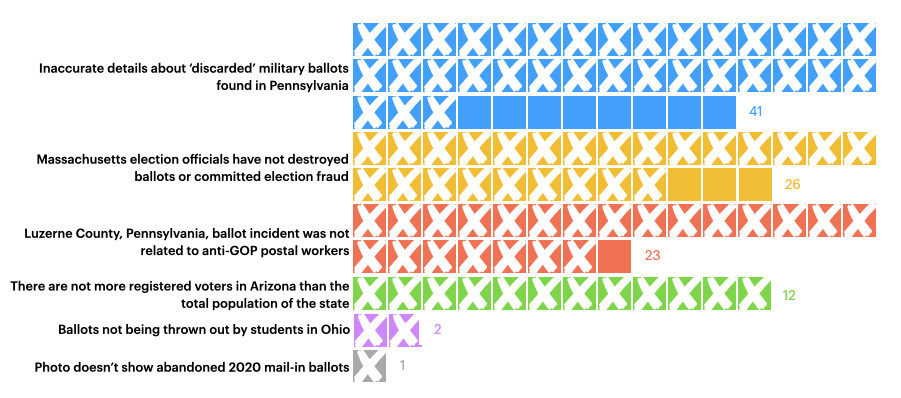
Figure 4: Breakdown of posts around mail-in ballots and election fraud. Crosses indicate the post did not link to the Voter Information Center.
False claims about the election were the most commonly fact-checked during the period we analyzed. We collected 255 posts espousing 16 unique falsehoods. Two unique claims about the nine military ballots that were discarded in Luzerne County, Pennsylvania, were fact-checked by The Dispatch, Lead Stories, and Reuters. We identified 64 posts that made misleading claims about the circumstances surrounding the ballots’ disposal. Both sets of posts portrayed the incident as a malicious attempt to discard Trump votes. Twenty-three baselessly blamed anti-GOP postal workers. Another 41 insinuated that officials at the Luzerne County Board of Elections intentionally discarded the ballots, at least seven of which were cast for Trump. An investigation revealed that a temp worker, three days on the job, appeared to accidentally throw them out without knowing who the votes were cast for. All votes will count towards the final election tally.
Stories repeating the claim that anti-GOP postal workers were responsible for the incident were spread by a number of prominent conservative outlets and figures including Diamond & Silk, Breitbart, and Sarah Palin’s page. In many cases, different outlets used identical or nearly identical headlines, and often had the same copy. Not only were a majority of the posts not fact-checked (even though other posts containing links to stories with the same title and copy were, as can be seen in Figure 5), but only two linked to the Voting Information Center.
Facebook has stated multiple times that it uses machine-learning and natural-language-processing technology to review article headlines and identify related stories in order to suss out misinformation across headlines making the same false claim. In a 2018 interview, Tessa Lyons, then a product manager at Facebook and now Director of Product Management at Instagram, praised the company’s algorithms, specifically noting their efficacy when dealing with links and headlines. “We’ve been doing this with links for a while; for example, a fact-checker in France debunked the claim that you can save a person having a stroke by using a needle to prick their finger and draw blood,” Lyons said. “This allowed us to identify over 20 domains and over 1,400 links spreading that same claim.” Yet, as Figure 5 illustrates, for the claim, “Luzerne County, Pennsylvania, ballot incident was not related to anti-GOP postal workers,” the automated processes appear to have largely failed to deliver.

Figure 5: Multiple instances of the same story were pushed by multiple sites including Diamond & Silk and Breitbart. Only one link had a fact-check label, only two stories linked to the Voting Information Center. Screenshots of the Breitbart link were shared on Instagram. And, even though multiple posts linked to the same Breitbart link, only had directed users to the Voting Information Center.
Several sites including Breitbart and Diamond & Silk were identified by NBC in an investigation in August that found Facebook was enabling conservative outlets to avoid “repeat offender” status. Typically, a page that shares false information more than twice in ninety days has their posts downgraded in users’ newsfeeds. According to NBC, senior Facebook employees were overseeing a process that allowed these and other conservative sites to remove strikes against them.
The other related debunked claim stated ballots for Trump were intentionally discarded by Luzerne County elections officials. This story was picked up by several prominent conservative outlets, though the actual events surrounding the claim were unclear. As new details trickled in, stories were updated. But links to the Voting Information Center were unevenly applied across the posts. And after the fact-check from the third-party partners came in, the “Partly False” label was also unevenly applied. Screenshots of Breitbart and PJ Media headlines on Instagram were given “Partly False” labels when shared by users, but the articles themselves are unlabeled. (PJ Media has since updated its headline to clarify that most, but not all, of the nine ballots were for Trump.) Similar posts by the Daily Caller, Daily Wire, and Sarah Palin received no such labels.
COVID-19
In March, Facebook announced it would put special emphasis on stemming misinformation related to the COVID-19 pandemic, including giving out $1 million in grants to partnering fact-checkers and launching a centralized hub on Facebook’s platform to house WHO-certified data on the virus. In April, Facebook announced it would actively remove harmful claims debunked by health experts, like the claim that drinking bleach can help cure COVID-19. Still, the company’s efforts failed to suppress what many disinformation experts termed “the infodemic,” and the conspiratorial Plandemic video was hard to contain on the platform.
Debunks related to COVID-19 and vaccinations accounted for 20 percent of fact-checks in the period we examined. A total of 275 posts corresponded with 15 claims debunked between October 1 and October 5. Two debunked claims, one around an image of “bacteria growth from face mask” and another about “forced inoculation plans,” were the ones fact-checked most thoroughly, according to our dataset. Across the 44 posts on the former, there were 29 fact-check labels as of October 6, when we first looked into this claim. In the case of the latter, we collected 37 posts, of which 26 had fact-check labels as of October 10. Despite the better numbers, inconsistencies in similar-image matching were consistent with our other findings.
Even as specific instances of a claim were fact-checked, the ones spreading more rampantly were never labeled. One meme attributed a false low number of deaths in Uganda to the widespread use of hydroxychloroquine. While eventually all instances we found of the meme were labeled “false” or removed, an article titled “Hydroxychloroquine is why Uganda, with a population of 43M, has only 15 COVID-19 deaths” spread unchecked. The article was published by an Australian foundation whose founder, Clive Palmer, a former Australian parliament member and mining magnate, claimed he bought nearly 33 million doses of the unproved drug in April. The link had over 50,000 Facebook interactions according to CrowdTangle, 8,000 of which were in public groups or pages.
While completely different versions of a claim, especially across different types of posts (images, links, video), can be hard to detect algorithmically, even minor language tweaks sometimes result in no labels. In one series of memes, a list of states were declared to be mask-free. While the original posts were labelled per the fact-checkers’ verdict, minor alterations to the text weren’t automatically flagged by Facebook’s algorithm. These included adding a state to the list or changing the order of the states in the list. In one particular case, the difference was simply changing “WY” to “Wyoming.”
“I don’t think it would be so hard for these cases,” says Kathy McKeown, the Founding Director of the Institute for Data Sciences and Engineering at Columbia University, who studies natural language processing. “I would guess probably volume has something to do with it and whether they’re exhaustively looking at everything.” Identifying similarity across different media types have their own challenges: the semantics of natural language processing; the resource-intensitivity of video; and the minor differences in images across screenshots, cropped images, and embedded images. Combining various machine-learning technologies is in itself non-trivial, especially as Facebook’s user base across all its platforms is larger than the population of any single nation state.
However, the company has successfully scaled up virtually every other aspect of its platform, and continues to create and integrate new products within their suite of platforms. But the problems with misinformation, hate speech, and radicalization on their existing platforms continue to fester.
“The least amount of money to get the max amount of insulation”
The platform’s size presents serious challenges to automating fact-check labels on Facebook. Last year, Zuckerberg questioned the scalability of the fact-checking program more generally, floating the idea of replacing professional fact-checkers with crowd-sourcing. “The issue here is there aren’t enough of them,” he said. “There just aren’t a lot of fact-checkers.” Yet Zuckerberg has pointed to the platform’s size as a net benefit. “We’ve built sophisticated systems to find and remove harmful content.” Zuckerberg said in his opening statement during a July 29 antitrust hearing on Capitol Hill. “Facebook’s size is an asset in those efforts.”
Facebook’s failure to automatically propagate fact-check labels on similar content across the platform falls short of its promise, to both its users and its fact-checking partners. The lack of progress on this front raises questions about how serious the company is about tackling this problem. Fact-checkers end up picking up the slack, labelling multiple similar posts that enter the fact-checking feed that is provided to them by Facebook. Vinny Green, the COO of Snopes (a founding partner of Facebook’s fact-checking partnership), told us in an interview that the queue’s clunkiness made their work “just not scalable. [Facebook] would not tolerate it in their own organization.” Snopes withdrew from the partnership in February 2019.
Today, fact-checkers have different approaches to addressing similar claims coming through different posts. One partner, for example, has an employee dedicated to applying fact-check labels from their existing repository to new posts carrying the same debunked claim. Another fact-checking partner often dedicates a day at the end of each week to using keyword searches to apply old fact-checks to new content that Facebook missed—time that could otherwise be spent addressing new claims. For another partner, dedicating fact-checkers’ time to searching for similar posts on Facebook’s platform isn’t a priority. Green shares this sentiment. “Facebook has found a way to pay the least amount of money to get the max amount of insulation,” he said.
If you are a fact-checking partner or have worked with Facebook on fact-checking, please get in touch here and here.
Methodology
In the last four years, Facebook’s fact-checking program has extended to fifty third-party partners globally, ten of which cover the United States. The fact-checking process is relatively straightforward: fact-checkers get access to a “queue” or “database” of claims populated by Facebook, and they independently choose which claims to verify. Facebook adds posts to this queue through a combination of user reports and their internal algorithms that scan posts looking for potentially suspect content. Once fact-checkers complete the verification process, they add the relevant fact-check label (Altered Photo, Missing Context, False Information, or Partly False Information) to the post in the queue and provide a link with a more detailed explanation. The fact-checkers we spoke to said this updates immediately on Facebook’s end. Further, in a December 2019 blog post, Facebook said, “We use image matching technology to find further instances of this content and apply the label, helping reduce the spread of misinformation. In addition, if something is rated false or partly false on Facebook, starting today we’ll automatically label identical content if it is posted on Instagram (and vice versa).”
With this project, our goal was to understand how consistent the Facebook parent company was in applying labels to content fact-checked by their partners across both Facebook and Instagram, especially during breaking-news events when the lack of verified information creates a breeding ground for viral rumours and hoaxes. For the purposes of this project, we focused on the first five days of October, from the time the president was diagnosed with COVID-19 to the time he was released from hospital.
Even though the news in 2020 has been non-stop, we chose these five days for the sheer volume and myriad of non-trivial news occurring simultaneously: a big breaking-news event in Trump’s diagnosis, election-related coverage around both the debate and mail-in voting, a constant stream of news around the pandemic and vaccination plans, and the daily news cycle.
In those five days, Facebook’s US fact-checking partners had looked into over seventy claims covering the topics listed above. Five days is a short period of time, but these seventy claims allow us to illustrate the many inconsistencies in Facebook’s algorithms that are responsible for labelling similar and identical content. Prior to October, we’d already collected anecdotal evidence of multiple claims on which fact-checking labels were not applied across the board. This included Biden’s alleged “teleprompter gaffe” (Figure 6), false declarations that the West Coast wildfires were caused by antifa arsonists, and a video of a Tucker Carlson interview where the guest claimed the novel coronavirus was man-made.

Figure 6: Various versions of the claim that Biden was using a teleprompter. The four screenshots from Instagram in the first column, highlighted in green all have fact-checks, but none of the ones highlighted in red have a screenshot. The verified account TeamTrump posted this to over 150,000 views. For all other accounts, we’ve removed the account details to either preserve privacy or to not provide oxygen to accounts prone to peddling misinformation.
The ten US fact-checking partners have a feed of claims they have investigated and the corresponding write-ups on their individual websites. These write-ups typically point to the original post—or an archived version thereof—that sparked the original investigation, which is what we used for our analysis. The original post is not necessarily always a Facebook or Instagram post, but that doesn’t mean those pieces of content don’t do the rounds on Facebook’s platforms too. To wit: a screenshot of a viral tweet can often be found on Facebook pages and groups as well as on Instagram.
For the purpose of this project, we were mostly interested in US fact-checks from October 1 to October 5. Differences among fact-checkers in the scope and format of their investigations created some challenges when gathering this data. Specifically, AFP covers territories not limited to the US, PolitiFact covers media not limited to Facebook, and USA Today doesn’t have dates against their write-ups on the front end of their website. This led us to tweak how we identified which fact-checks to add to our list from these three partners: for AFP, we only added checks from their US feed; for PolitiFact, we only looked at articles tagged “Facebook Posts”; and for USA Today, we went into the HTML and looked at the ‘datePublished’ metadata to ensure it fell within the date range we were interested in.
To search Facebook and Instagram, we relied on a combination of the search functionality on Facebook’s website and CrowdTangle, a Facebook-owned social-media insights tool. Facebook’s search interface allows us to access public posts by individuals whereas CrowdTangle surfaces posts from pages and public groups, but not individuals. Therefore, our analysis is strictly based on posts in public groups and pages; we have no window into what happens in private groups or individual posts. Other research and reporting has shown, though, that misinformation and hate thrives in private groups. CrowdTangle does not provide data on whether a post has been fact checked or not. Hence, upon identifying posts that were either identical or similar to content fact-checked by the fact-checking organizations, we manually checked each one to see if a label was applied to the post or not.
For each fact-checked post, we searched keywords and phrases from the original claim and looked for websites that were mentioned in the verification article or the claim itself. Searching for keywords or phrases on CrowdTangle also pulls up images containing the text identified by Facebook’s internal optical character recognition (OCR) algorithm. Optical character recognition technology allows text to be extracted from non-text files, thereby making that content easier to index and search. This allows us to pull up identical memes or screenshots of tweets. When we found any content that was similar but not identical, we pulled in the key identifiers from the new content and did another search. To ensure thoroughness, this was a manual process. You can see the queries we ran for each claim and the categorizations here.
We attempted to find at least twenty examples with at least a single share for every claim. In some cases, we were unable to find a single post, but for others we documented anywhere from two to fifty posts containing the same piece of debunked content. Overall, for eight of the posts, we were unable to find any matches in CrowdTangle. The manual data-collection process started on October 6 and ended on October 14, which pulled in the post, author, link, fact-check status and label, and who the fact-checkers on the post were. We then ran an automated process on October 16 to see if the posts initially identified were still active, and whether any of the claims had received a fact-check label after our initial data collection. We manually confirmed all discrepancies found between our original dataset and the automated collection on October16.
It is worth highlighting that the posts we found aren’t all the relevant posts—and quite possibly not the most interacted with posts—on Facebook and Instagram. For example, one story claimed that the coronavirus vaccination plan relied on forced inoculation. When we looked for the link to the story on CrowdTangle, we found that while there were over 700,000 interactions with it across all of Facebook including private groups and posts, only 42,000 of these were on public posts. Private posts and conversations in private groups are hidden, and we don’t have a window into the spread of misinformation—or presence of fact-checking labels—on those channels.
Update: A previous version of this article stated that no US-based fact-checking partner was a recipient of the COVID fact-checking grant program; PolitiFact was a recipient.
Has America ever needed a media defender more than now? Help us by joining CJR today.


