
Sign up for the daily CJR newsletter.
The International Consortium of Investigative Journalists hit the mother lode when it published the first of its dozens of exposés on the off-shore tax-haven business back in April.
The series, based on the mammoth database obtained, somehow, from two unlucky companies involved in the giant and shady asset-hiding business, continues to reverberate. The number of investigations, reforms, and responses it sparked around the world —from Cananda to Mongolia to the Philippines to the E.U.—is still expanding and is documented at length here. One of the most crucial bits of fallout came in May when David Cameron at a White House press conference called for an end to the “scourge of tax evasion,” which is all the more significant since the U.K. is, of course, a haven hub. Not coincidentally, the issue is on the G-8 agenda this week.
As I wrote at the time, this has to be a landmark of some kind: 86, now 112 journalists from more than three dozen news organizations, including The Washington Post, Le Monde, the Guardian, the Canadian Broadcasting Corp, etc., in 46 58 countries analyzing 2.5 million records relating to 120,000 companies in ten offshore jurisdictions. What’s especially significant is that many journalists worked on the project for more than a year: that’s scores of thousands of reporter-hours, as many as a 100,000 hours or more, by my calculations. The roster of staffers is here.
Now, the entire database itself has come online. Released over the weekend, it’s an elegantly designed Web application that allows users to look up customers of the off-shore haven business, which sets up shell companies in jurisdictions that allow the real principals to be concealed from the public and, usually, even authorities. The database is relational and allows users to draw the connections between individuals and the entities associated with them, and vice versa.
Type in the name of, say, a certain “Dr. Herbert Stepic,” and you’ll see that the now-former CEO of Raiffeisen Bank, one of the biggest in Eastern and Central Europe, has ties to a couple of off-shore entities, including one called “Takego Holdings Limited.”
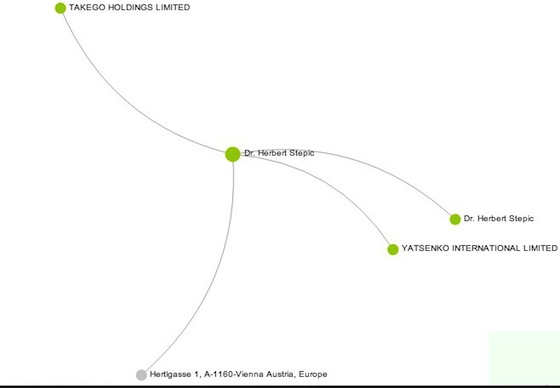
Type in that name, and you’ll see that it has ties to other entities, including some whose names are being, as ICIJ puts it, “temporarily withheld,” as the center continues to pursue new stories based on the database.
The tax-haven series and database has gotten a lot more traction internationally than it has in the U.S., probably because the biggest stories involved overseas officials and businesspeople. But from a journalism standpoint, it’s interesting on several levels:
—On one hand, the project has so far been strictly a product of professional journalism; the aforementioned small army of reporters and editors, under ICIJ director Gerard Ryle, have all be affiliated with one journalism institution or another. The product so far as been more than 50 news stories, written in conventional (if not always elegant) style. The data have been scrubbed, for instance, of email addresses, telephone numbers, passport and bank account information, financial transactions, specific assets, and and photos. So this was no data dump.
—But, with the release of the database, the project now becomes a crowd-sourced affair. The ICIJ is calling on readers to help identify future stories or send along tips or corrections, and with a database of this size—and with the global interest the project has generated —the crowd could prove to be a valuable asset. Or not. But we’ll know soon enough.
—“Big Data,” the use of new technology to mine massive amounts of information for stories, is held out as the next breakthrough in journalism, and so far this project has been mark in its favor.
Anyone who thinks Big Data projects are easy or inexpensive, would do well to read Giannina Segnini’s piece on the painstaking efforts by staffers at La Nación Costa Rica to clean and meld data in numerous formats and tables, with misspellings, abbreviations, weird punctuation, etc., into something resembling usable form. Just eliminating duplication proved a huge challenge, requiring, among other things, the use of a library developed by MIT and named Vicino that performs “nearest neighbor searching and clustering” and an algorithm, called SIMIL, that looks for similar strings of data. One important consideration, for instance, was making sure that the people with similar-sounding names were in fact the same person.
—Then there’s the business model: ICIJ is an offshoot of the Center for Public Integrity, and is philanthropically funded. Recent ICIJ funders include: Open Society Foundations, the David and Lucile Packard Foundation, Pew Charitable Trusts, and the like. The collaboration with commercial news organization makes it something of a hybrid, a model that has been put to good use elsewhere and makes all sorts of sense. Whether nonprofits can ever make up for what’s been lost in the news business is an open question. But this arrangement is on scale that’s vastly larger than those tried so far. Coordinating among so many organizations is a job unto itself. And given the expense and risk of such grand investigative projects, the more resources available the better.
For a few reasons, then, this type of project is worth watching as a kind of ad-hoc model for the Great Stories, the longform, labor-intensive projects that, once again, prove indispensable.
Has America ever needed a media defender more than now? Help us by joining CJR today.



