

This research is generously funded by the Tow Foundation and the John D. and Catherine T. MacArthur Foundation.
Introduction
Early in our first interview, a veteran news executive began the story of their interactions with technology companies over the past decade by taking a deep breath.
“You know,” the executive said, “it’s been a long, strange trip.”
It’s fitting that these were among the first words we heard in our study of the relationship between journalism and generative AI, the latest turbulent phase of the purportedly “post-platform era.” Failed products, misguided strategies, and an incompatibility with the demands of truth-based publishing have characterized many tech companies’ efforts to engage with news organizations, along with inadequate financial support that arrived sporadically and was tied to conditions. The most promising “innovations” in news have instead come from journalists and newsrooms finding strategies that protected them from the business models of platform companies. Nonprofit newsrooms have been forced into existence by Alphabet and Meta’s duopolistic grip on advertising revenue, while direct-to-consumer routes such as newsletters and podcasts have come into their own as social media and search platforms have deprioritized or even removed news.
The Tow Center for Digital Journalism has been researching the evolving relationship between platforms and publishers since 2015. Our 2019 report, “The End of an Era,” documented a period when publishers were coming to accept that the core premise of the social media era — that the future of journalism lay in targeting audiences on Facebook, Twitter, Snapchat, Instagram, Apple News, Google, and other platforms — was wrong.
In its stead came a renewed focus for publishers on fostering the direct relationships news organizations had formed with their most dedicated audiences, which they realized were also their best shot at sustainability. “The platform stuff was a distraction,” one publisher noted at the time. “It was a good lesson, an objective lesson in: Listen to your audience.”
Fittingly, that period is almost bookended by the transition from the so-called Death of the Homepage circa 2014 — characterized by headlines like “The homepage is dead, and the social web won — even at the New York Times” — and its rebirth as part of a renewed focus on leveraging publishers’ owned-and-operated platforms to foster direct relationships with their audiences through newsletters, apps, podcasts and, yes, websites.
A lot has happened in the meantime. For one, Google and Meta, Facebook’s parent company, whose deep involvement in the news ecosystem made them key protagonists in our previous reports, went from ramping up their respective big-money news initiatives and licensing programs — including the Facebook Journalism Project, Facebook News, the Google News Initiative, the Google Digital News Initiative, and Google News Showcase — to reducing their focus on journalism (Google) or withdrawing entirely (Facebook) in the space of a couple of years.
The initial displays of financial generosity came against a backdrop of mounting regulatory pressure around the world. In October 2020, Google CEO Sundar Pichai announced the company was committing “an initial $1 billion investment in partnerships with news publishers and the future of news” over three years through a new product called Google News Showcase. Not to be outdone, Facebook announced in February 2021 that it would commit $1 billion to journalism over three years.
Then the winds shifted. Facebook was first to show its hand in 2022, moving engineering and product resources away from its News tab and Bulletin newsletter platform, which was ultimately shuttered, along with Instant Articles. The platform also opted not to renew its News tab licensing agreements, and made substantial layoffs across its news division. The following year, it responded to the Canadian government’s passage of the Online News Act by immediately blocking access to news on Facebook and Instagram in Canada, as it had briefly done in Australia in 2021 to protest the proposed News Media Bargaining Code.
Google signaled its retreat from journalism through a series of similar moves in 2023, when the search giant responded to proposals in the California Journalism Preservation Act (CJPA) by threatening to pull links to California news sites from Google Search, pausing licensing arrangements with the state’s news outlets through Google News Showcase, and threatening to pause a planned expansion of its $300 million Google News Initiative across the country. Later that year, the company made substantial cuts to its news division.
Following its takeover by Elon Musk in late 2022, another major player in the social era, Twitter — which Musk rebranded as X — made a series of moves that were hostile to news organizations, including removing verification checkmarks from accounts that didn’t pay $1,000 a month for the platform’s new Verification for Organizations status or purchase enough advertising to qualify for free verification; labeling public service news organizations like the BBC and NPR “state-affiliated media”; and throttling the load speeds of links to news sites such as The New York Times and Reuters, as well as rival services including Threads, Instagram, Facebook, Bluesky, Substack, Mastodon, and YouTube.
As the old guard retreated, however, a new band of disrupters rose to prominence, pledging to harness a subset of artificial intelligence technology to revolutionize the information ecosystem. These newcomers included Perplexity, founded in 2021 to challenge Google’s dominance with an “AI search engine” that “searches the internet to give you an accessible, conversational, and verifiable answer,” and OpenAI, an AI company founded in 2015 with backing from the likes of Elon Musk, Peter Thiel, and LinkedIn co-founder Reid Hoffman, with a stated mission to “ensure that artificial general intelligence benefits all of humanity.”
Launched in November 2022, OpenAI’s flagship chatbot, ChatGPT-3, instigated an extraordinary boom in generative AI, taking large language models (LLMs), a hitherto relatively obscure technology mostly unknown outside the specialized fields of computer science, academia, and business, and thrusting it into the public consciousness almost overnight. According to Time, the tool had 100 million active users within two months, a landmark it reached seven months ahead of TikTok and more than two years earlier than Instagram had. As early as December 2022, ChatGPT’s meteoric rise “led Google’s management to declare a ‘code red,’” according to the New York Times. In February 2023, a month after extending its multibillion-dollar investment in OpenAI, Microsoft announced that OpenAI’s generative AI technology had been integrated into its Bing search and Edge browser products.
The launch of ChatGPT also serves as a useful — albeit rough — starting point for the (generative) AI era of the platform-publisher relationship. Generative AI intersects with journalism in a number of ways, some of which highlight key distinctions from social media. The first — as anyone who has attended a journalism-oriented conference or training session or seen a research proposal or school curriculum since late 2022 will be acutely aware — centers on the push to use generative AI tools for tasks including, but not limited to, analyzing large datasets; converting news outputs into different formats; translation; headline and summary generation; and drafting copy for emails, internal reports, or social media posts.
The second, rather more contentious intersection — which is the central topic of this report — centers on the fact that the text data used by AI companies to train the LLMs that underpin their generative AI products includes a significant amount of published journalism. The Times, for instance, found that its content accounted for 1.2 percent of a recreated version of the dataset used to train OpenAI’s ChatGPT-2. What’s more, among the applications being developed with this scraped data are generative search products that summarize web content, such as news articles, on-platform, reducing the need for users to click through to the source material. The pitch from Perplexity, whose founders included former employees of Facebook and OpenAI, promises “instant, reliable answers to any question with complete sources and citations included. There is no need to click on different links, compare answers, or endlessly dig for information.”
This appears to be true: As of May 2025, many news publishers are experiencing sharp declines in referral traffic from traditional search engines, particularly Google, which has been expanding its AI Overviews feature and experimenting with AI-only search results. Meanwhile, data from Comscore and Similarweb indicate that generative AI platforms like ChatGPT and Perplexity have yet to emerge as significant sources of news traffic, contributing only a negligible share of visits to news websites. A February 2025 report by TollBit, a marketplace for publishers and AI firms, found that AI search bots on average are driving 95.7 percent less click-through traffic than traditional Google search. This drop may stem from users’ growing preference for “zero-click” experiences; a Bain & Company survey published the same month found that 80 percent of consumers rely on AI-generated summaries or search page previews without clicking through at least 40 percent of the time. As Axios reported in April 2025, the decline in traditional search referrals is “unlikely to be offset by new AI search platforms in the foreseeable future, if ever.”
AI companies’ recent rollouts of generative search tools that promise fresh, reliable, up-to-the-minute content highlights a key distinction from the social era, insofar as it undermines tech companies’ ability to claim that they don’t need (or want) news output on their platforms. Explaining Meta’s decision to block news from Australian outlets in 2021, Nick Clegg, Meta’s VP of public affairs, said, “We neither take nor ask for the content for which we were being asked to pay a potentially exorbitant price.” The recurring line in Clegg’s statements about the company’s retreat from journalism in Europe, Australia and the United States, and Canada was: “We know that people don’t come to Facebook for news and political content.”
AI companies need reliable, verified data to train and ground LLMs, and have scraped vast quantities of news content to do so. As Jessica Lessin, founder of The Information, argued, “It turns out that accurate, well-written news is one of the most valuable sources for these models, which have been hoovering up humans’ intellectual output without permission.”
That genie can’t be put back in the bottle, Clegg has acknowledged more recently, “given that these models do use publicly available information across the internet.” Therefore, the negotiating position is no longer that they don’t need or want news output, but that they don’t need to ask or pay for news content.
Among news organizations of the view that AI companies have infringed copyright and stolen their intellectual property, a few have weighed whether to litigate or seek licensing agreements. The Times’ 2023 copyright infringement case against OpenAI and Microsoft — OpenAI’s primary investor, exclusive cloud provider, and strategic partner — is the highest-profile example of the former, while several dozen publishers have entered into licensing agreements with OpenAI or revenue-sharing agreements with Perplexity. But most news organizations are stuck watching from the sidelines. Meanwhile, Google and OpenAI are attempting to circumvent the legal battle altogether by lobbying the Trump administration to weaken copyright restrictions on AI training and codify a right for U.S. AI companies to train their models on publicly available data largely without restriction.
While upstarts like OpenAI and Perplexity have certainly caused a stir, established names such as Microsoft, Apple, and Google have strained to portray themselves as allies of the news industry while facing tough questions about their handling of publishers’ intellectual property. Microsoft, for example, which has historically paid to license news for its MSN portal and positioned itself as the friendly alternative to Facebook and Google when the News Bargaining Code was making its way through the Australian courts, has cozied up to publishers with “several collaborations with news organizations to adopt generative AI,” even as it is being sued by multiple news organizations that accuse it of infringing their copyright in order to create that very same generative AI technology.
All told, it’s fair to say the AI era of the platform-publisher relationship hasn’t gotten off to the smoothest start, but the same could be said about every previous era. “Generative AI has increased the gravitational pull” of some platforms, the news executive quoted at the top of the chapter noted, while others, like X, have less sway. “OpenAI didn’t exist but now is a thing; Microsoft was less of a player and is more of a player,” the executive continued. “The challenge that we have right now is that news, as an industry, tends not to learn terribly well from our past experiences and mistakes.”
This assessment neatly encapsulates a motivating force behind this report. Certain aspects of the AI era are new, while others are eerily familiar; there are opportunities for both news outlets and tech companies to apply the lessons of the past, but structural similarities mean that some mistakes may be repeated. (Sitting outside the scope of this report are questions about the safety and ethical nature of the use of these tools in newsrooms, as well as the impact the widespread adoption of generative AI tools for both content production and consumption might have on the health of the information ecosystem.)
Conscious that this era — and indeed, AI technology as a whole — is in its nascency and critical episodes are yet to fully play out, the primary goal of this latest iteration of our ongoing study is to assess the health of the relationship between platforms and publishers during this early but already stormy period. To achieve this, we conducted 34 semi-structured interviews with representatives from the news and technology industries from the U.S. and Europe: 24 news executives, editors, product managers, and newsroom AI specialists; six former platform executives; two representatives from AI companies; and two AI experts. All interviewees were promised anonymity in accordance with the protocol approved by the Columbia University IRB (Protocol Number: IRB-AAAV1429). Given our purposive sample, no claim is made to generalizability. Instead, we explore the key themes that emerged from our conversations, which took place between May and October 2024 and lasted 30 to 75 minutes each.
This report is a survey of the relationship between publishing companies and the technology and platform companies that by their actions and products shape the field of journalism. Outside the scope of this report are questions about the safety and ethical nature of the use of these tools in newsrooms, as well as the impact the widespread adoption of generative AI tools for both content production and consumption might have on the health of the information ecosystem.
The Structure of this Report
This report contains six chapters. In Chapter 1, we present a brief overview of how interviewees characterized the status of the relationship between news publishers and technology companies as of mid-to-late 2024. While we sought to avoid repeating the well-documented history of when, how, and why the relationship between platforms and publishers disintegrated, this chapter provides important context about the extent to which news workers’ dealings with AI companies are being shaped by past experiences.
In Chapter 2, we begin our exploration of how generative AI has started making its mark on news organizations. Rather than duplicate excellent work that has already been done exploring specific use cases and workflows, we focus instead on interviewees’ attitudes toward the utility of generative AI; the extent to which they felt it was delivering on its promise; the levels of understanding about the technology in their organizations; and the manner in which that understanding shapes strategic decisions and demands.
In Chapter 3, we offer a detailed discussion of how interviewees are thinking about some of the key issues stemming from the rise of new and emerging third-party platforms that use generative AI to summarize journalism, such as Perplexity; OpenAI’s search tool, which was integrated into ChatGPT in October 2024 after the conclusion of our interviews; and the AI Overviews that Google has begun integrating into its market-dominating search platform. We begin the chapter by addressing the elephant in the room: the extent to which unresolved issues around copyright and intellectual property cast a shadow over every aspect of our conversations. In particular, we discuss an aspect of this knotty debate that recurred throughout our interviews: the speed at which the respective parties may want to seek a resolution. This is followed by a discussion of other common themes pertaining to disintermediation, the new value exchange, audience traffic, and data.
Chapter 4 is dedicated to a discussion of licensing deals, one of the foremost ways in which AI companies, most notably OpenAI, have started to formalize relationships with news organizations and indicated that they see some financial value in journalism. Having discussed the broadly positive view that, for all their limitations, these early deals set an important precedent in regard to journalism’s financial worth and the need to pay for access, we explore interviewees’ attitudes toward these arrangements, which run the gamut from “a really scary moment for journalism” to “it could be free money.” To round off Chapter 4, we touch on some of the nonfinancial aspects that interviewees identified as key considerations in any formal arrangements with AI companies.
In Chapter 5, we delve into some of the deeper issues that emerged regarding the relationship between AI companies and news organizations, such as a lingering sense of betrayal and resentment among publishers exhausted by earlier dealings with technology companies; the extent to which disruption from the highly competitive arms race around generative AI is already having real-world implications for some interviewees and unsettling others; how incompatibilities between platforms and publishers could spell trouble if they go unaddressed before the AI era hits full swing; concerns about wider issues on the horizon; and recurring calls for greater collaboration both within journalism and across the two industries.
Finally, in Chapter 6, we reflect on our findings and unpack the key areas that seem primed to determine the next phase in the uneasy marriage between platforms and publishers.
Platforms and Publishers in 2025: A Bird’s-Eye View
Having absorbed the well-documented lessons around tech platforms’ unreliability as partners (crudely, that monetization, traffic, audience, visibility, and publishers’ access to representatives can fluctuate or disappear at a moment’s notice — if they existed in the first place), publishers have long viewed strong, direct relationships with their audiences as vital to their hopes for a sustainable future, ideally through their owned-and-operated properties.
Speaking of a historical pitfall that contributed to this reprioritization and emerged as a concern about third-party news summarization platforms (see Chapter 3), a news executive said, “A lot of the audience that we could have built in spaces that we controlled, we built elsewhere and then we rented, in a sense, and then the landlord evicted us and so we didn’t get to keep any of those improvements — they were all in a space we didn’t own.”
But despite platforms’ checkered history and talk of a post-platform era, an early theme to emerge in our interviews was that many of the platforms that mediate publishers’ relationships with their audiences remain unavoidable. An interviewee with deep experience on both sides of the platform-publisher divide typified the views of many: “I don’t think there’s any way around the platforms. The platforms are … where the audiences are. Where there are new audiences, where there are old audiences. … So as a publisher, you have to be there.”
Another news executive said that platforms today are crucial for publishers’ efforts to “be part of a person’s media diet. … It’s about finding those new audiences, reminding them that our brand exists and that we have great things to say, and it’s about learning how to translate our brand and tell stories in new formats. That, I think, is a critical level of experimentation.” The question, they continued, therefore becomes, “How do we utilize these places where we know there are large audiences and try to get them to engage with us?”
Continuing a central theme from our last report, most of the publishers we spoke to in summer 2024 said they had refined their distribution strategies to focus on the handful of platforms that make the most sense for their brands. Highlighting the extent to which new and existing audiences factor into many platform strategies, a news executive with deep experience negotiating platform partnerships summarized their key requirements with a three-point checklist:
- Is it a healthy and safe environment for our brand and audience?
- Can we use it to generate direct relationships with our audience in our own environment?
- Is there a reasonable value exchange between us and the platform, i.e. are we getting enough out of whatever we put in?
Given tech platforms’ ongoing, albeit uneven and reconfigured, importance to news, a recurring sentiment among publishers — including some whose organizations have been stung by misplaced optimism about platform partnerships — was the importance of maintaining open lines of communication with technology companies to understand how emerging innovations and priorities could affect their businesses and the ecosystem at large.
One news executive described their current approach as “more like a defense and offense strategy all at once.”
“How do we play defense with these guys in a way that’s not gonna turn us off from the internet?” the executive asked. “Obviously they’re still crucial partners and crucial places where the audiences are spending a lot of time, and we’re going to have to find the right ways to work with them, but [only] in a way that’s ultimately going to be additive to the business and strategic.”
The view that it is better to be on the inside, gathering knowledge about the prevailing direction of travel, than on the outside playing catchup was echoed by an executive from a large international subscription-based outlet, who said, “Our experience with technology has been that if you shy away from it and ignore it, it’s not going to do you any favors. If you try [to] lean into it and understand what it’s about and what it’s doing, then generally you’re going to be in a better place to make a smart decision.”
A news executive who moved into the nonprofit sector after many years with for-profits captured the potential risks of engaging with tech companies when they said: “An approach I’ve always had to conversations with platforms has been to say yes.” But yes to what? The executive continued: “Go be in the room and hear what’s going on and hear what they have to say. With OpenAI and Google, that outreach has already begun, so if that continues, then the conversations are something that I welcome, particularly to understand where they’re headed. But as far as partnering goes, I would have more follow-up questions than a younger me did, and would go into it with a bit more trepidation now.”
The bluntest articulation of this perspective came from an executive of a legacy publication who said, “I think you have to engage, because if you’re not engaging you don’t even know what these deals are. It’s better to be engaging than to stand back and say, ‘I’m having nothing to do with this.’ I don’t think we have the luxury of that. We may still get fucked in the process, but it would be better to at least understand where those things are going and to be able to utilize that.”
Increasingly, however, journalism partnership teams at some of the biggest players have shrunk or been disbanded, meaning that many news organizations no longer have anyone to talk to at the platform companies. An AI leader at a large international legacy news organization with good access to platforms acknowledged that their company was an outlier: “Relative to the wider industry, our relationship is a pretty good one. I say that because we have a direct line into different platforms, which is quite unusual.”
More typical was the frustration expressed by an executive news editor at a major international outlet who had come to accept that technology companies tend to pick up the phone only under specific circumstances. “If you don’t have something that they are explicitly looking for, you will be — to be blunt about it — probably ghosted,” they said. “It is incredibly difficult to find a person in any of these technology companies right now who wants to just talk about news or distribution.”
There was a feeling that AI companies’ need for verified, high-quality, real-time information to train their LLMs might motivate them to improve their relationships with news organizations. Interviewees from AI platforms claimed to be conscious that work is needed to prevent the kind of hostility between technology companies and the news industry that prevailed during earlier eras.
“We have to start by acknowledging that tech needs journalism, and journalism needs tech,” said a current platform leader with a journalism background. “We have to recognize the unique role that journalism plays in society and in the world and in our own products. If we create economic conditions or functional conditions that pose threats to journalism, that inhibits our ability to have a product that’s informed by good information and put it out there. So we do have common ground there. Are there questions that we haven’t resolved yet in that discussion? Absolutely. But I think if we can remember that we need that symbiotic relationship, hopefully that’s what powers the conversation into the next chapter.”
Similarly, a representative from another prominent AI player insisted that their company’s future prosperity is intertwined with that of the news industry. “We realize … we need to work very closely with the publishing industry, because our success is tied directly to the success of a thriving journalism and digital publishing ecosystem — AKA, we know that journalists produce high-quality verified facts, and in order for [our tools to be able] to answer some of [our users’] questions, we need the continual production of that type of information. Basically, there is no world in which [AI platform] is successful but publishers are not.”
Moreover, they hoped to avoid the ephemeral sugar rushes that defined earlier phases of the platform-publisher relationship. “There was a lot of short-term thinking and trying to chase the money, because newsrooms were really having a challenging time, so they probably needed to go where the money was,” the AI representative said. “But there was not a lot of long-term thinking. And one of the best things about my time at [previous platform], and what I’m trying to infuse into my role here at [AI platform], is really trying to think more long-term and build things that will scale, rather than the short-term programs or playbooks.”
While this is an admirable position, the broad trend at tech companies toward eliminating or shrinking news partnership teams, making them an even smaller cog in a much larger machine, will necessarily limit their effectiveness. As a former platform executive admitted, “If you’re operating at scale as a big tech company, you’re trying to do the right thing,” but ultimately “all the structures … end up being the least worst ones that you can do.”
The Generative AI Era
OpenAI launched ChatGPT-3, the chatbot widely credited with bringing generative AI into the public consciousness, at the end of November 2022. By the time our interviews began some 18 months later, the initial hype around generative AI had largely subsided. Instead, we typically found news workers trying to temper their weary disenchantment with optimism that the youthful technology might still deliver on its promise.
One CEO’s assessment crystalized the general mood: “There was this unbelievable enthusiasm, obsession, curiosity, early adoption of the platforms and tools. And now I think there’s a bit of disillusionment because [AI companies] don’t seem to have really cracked a genuinely viable product or genuinely transformational use case.” However, this person noted that user behavior or the application of these technologies might change or be disrupted in years to come.
An executive at a major global news organization put it slightly differently. “I think generative AI technology is so transformational, and I’m not even sure the creators of the technology fully understand what the applications are, or the primary use cases,” they said. “It’s a clever piece of technology, and everyone is searching for the transformative, once-in-a-generation idea that is going to propel it into the public consciousness. I haven’t seen it yet.”
At the more cynical end of the scale, a policy executive at an international newspaper who lamented the time, energy, and money being poured into “chasing this illusion that one general-purpose technology is going to solve all of the industry’s problems,” said: “Never have I seen so many innovations that were already ongoing being trumpeted as completely new [as I have] under the banner of generative AI, just because it’s highly sexy and the thing that everyone wants to talk about at conferences. We spend so much time and energy and money on these technologies because people are chasing the hype.”
While most interviewees could reel off a litany of ways their organizations are using generative AI behind the scenes, many also noted that the immaturity of the technology means any larger impacts on their workflows, practices, products, and businesses will only come into focus later. “It’s still such early days that it’s really hard” to predict the potential use and impact of the technology, an executive from a major legacy publisher said. “There’s just a lot of noise in the system, so it’s hard to dissect it all and for us to say what we need to do differently.”
One thing that quickly became clear is that many news outlets are investing significant time and energy in controlled experimentation with generative AI, using it for a range of tasks from transcribing interviews, drafting headline ideas, and summarizing articles, to repurposing and reformatting existing work, building interactive bots, and optimizing content distribution. But while a large majority of interviewees from the publisher side could reel off a range of such internal experiments, most stressed that even the most promising were unlikely to move to production any time soon, if ever — particularly where they were audience-facing. They considered the technology too unreliable to risk the damaging implications for brand and audience trust of publishing confabulated nonsense.
“The problem,” noted an executive at a large international public service news organization, is that the AI output “has to be perfect.” Their outlet, they added, cannot, for example, “have a story about [our] chatbot giving incorrect or malicious or harmful advice to a child. Other companies might be able to, but we can’t.”
An executive from a major international legacy newspaper brand said, “[Given] the unreliability of large language models, [their] propensity … to hallucinate means you’d have to be either a very brave or a very foolish publisher to put your brand reputation in jeopardy at the moment by putting AI technologies in a position where they’re publishing stuff to consumers that suggests that it’s original journalism.” Yet a number of publications have gotten into hot water in recent years for publishing low-quality AI-generated content.
Even in the rare instances when interviewees could share audience-facing examples that have made their way to publication (complete with prominent notices about the experimental nature of the tool), they still emphasized the guardrails that had been implemented to minimize risk. Describing the design of a chatbot that draws on the outlet’s deep archive to answer questions about a specific topic, an AI leader at a large legacy outlet said it had been important to identify a “safe” topic because in that case, “[g]etting something slightly wrong or framing it slightly wider rather than narrower … you’re not likely to have a real delta between what the asker asked and what we respond with. But [if] you look at nuance like that around a political issue, it can be really problematic.”
Adding to brand integrity concerns and the unreliability of foundational models, interviewees also pointed to lack of audience appetite as a reason for prioritizing experimentation instead of racing to production. An executive at a global public service news outlet said, “We are an organization that relies on trust. You can’t be a public broadcaster unless you protect your trust with the audience. And the audience isn’t yet at a place with generative AI where it believes it is necessarily a good thing. Until audience expectation and audience attitudes to generative AI move, there is too much risk for a public broadcaster like [ours] in going too quickly into that space.”
For organizations of this mindset, there is a fine balance between avoiding the risks that come with premature moves and being overly cautious and getting left behind. As this executive said, “You get into quite an interesting strategic conversation, which is you don’t really want to be the leader in the space, you don’t want to be the first mover — you probably want to be the second or third mover. Because you want to learn and absorb learning before you deploy. Because in a trust-based organization like [ours], the risks are too high to pioneer.”
In the absence of audience demand, the CTO of a for-profit outlet described experimentation partially as a means of preparing for a future uptick: “Internally, we have a lot of discussion that is like, ‘When do we take it from experimentation into heavier product development builds or into making it a first-class citizen?’ But the revenue incentive isn’t there yet. Our clients aren’t begging us for generative AI tools just yet, right? So it feels like the time is right for us to continue doing experimentation, so that’s what we’re doing.”
Despite their personal reservations, this technologist added, “There are definitely folks in our organization, especially senior leadership, that honestly believe that this is an iPhone or electric car kind of moment. And they feel it is important we be familiar when the curve goes more hockey stick, right? So when the adoption rates start to soar and when our [subscribers] begin to demand features from us, we want to be ready to go.”
Indeed, interviewees whose organizations had the capacity to experiment with generative AI described a wide range of rationales behind their organizations’ forays into the technology. Some had dedicated research and development teams that recognized unique opportunities in the new technology, having experimented with machine learning and artificial intelligence. For others, responses ranged from sharp pivots motivated by belief that the technology will live up to its transformative billing to curious experimentation for which generative AI was almost a solution in search of a problem.
An audience executive at a for-profit digital native recalled, “There was a really interesting moment in a meeting where it became clear that the policy had just flipped overnight. Previously it had been, ‘Hey, we’re researching and approaching this with caution,’ and all the usual language around that. Then overnight it was, ‘Your 2024 goal is to use AI as much as you can and to learn as much as you can about it in that way.’”
A significant number of interviewees highlighted uneven levels of knowledge about generative AI within their organizations, particularly among the most senior decision-makers. “Within news organizations, there is a lot that we don’t know,” an executive at an international nonprofit news outlet acknowledged. “Part of it is because it’s really complex what generative AI platforms do, and so for the less technical decision-makers, there’s a much greater hill to climb to understand exactly what’s going on there. I think that most of us, beyond the people who are creating these platforms, don’t actually really fully understand what will happen down the line, or what the leadership of an OpenAI or a Google has in mind for these platforms.”
An interviewee with deep experience on both sides of the platform-publisher divide said, “If you talk to an executive in a publishing house about AI and how it works, what it enables us to do now, and what it could look like in just two years’ time, it’s just so mind-boggling [to them] that they can’t follow along.”
In fact, a number of conversations illustrated how this mismatch in knowledge has already created headaches for newsroom staff. Raising a complaint reminiscent of some of the industry’s earliest web experimentation, an AI strategist at a news agency said, “We’re getting our direction from the top down. And I will say the top is not well informed. So the use cases they’re asking us to pursue are not very good ones.” While AI can work well for translation, it’s “a little dangerous” for a large news organization to use it to write headlines or summaries, they said. “They’re not letting our team lead on this. They’re instead trying to lead it in a way that’s managed — probably overly managed.”
A CTO described the balancing act required to respond to the sometimes vague and/or impractical demands of upper management while moving forward with day-to-day development work: “When I talk to my teams about this, one of the things I say to them is, ‘Look, you need to take these pushes from our execs and from the boards seriously, but not literally. They don’t know how to ask you precisely what they want. They’re telling you there’s a problem here.’ And I believe that there are real problems to be solved that generative AI and, more broadly, autonomous agents working on my behalf can solve. It’s our job to figure out versions of that that are sensible, and not boil the ocean or build really dumb products.”
Elsewhere, a digital director at an international outlet described misplaced suggestions to delegate content creation tasks to generative AI. “It’s usually around e-commerce, saying, ‘We need 10 articles about lipstick, or about foundation. That’s really dull for a person to write, so just get an AI to do it.’ But that’s going to be really dull for a human to read. And it’s not going to rank, because [Search Generative Experience] is going to squeeze it.” (Search Generative Experience was Google’s name for what became AI Overviews when generative AI summaries were introduced as an experimental feature in May 2023.)
Some interviewees also suggested that the uncertainty about how generative AI might impact news publishers partly stems from a lack of clarity on the part of AI companies themselves. An executive news editor at a major international outlet said, “No matter what anyone will tell you, I don’t think that they have the necessary insights yet to know where all of this is truly going. I don’t think we know what the near future exactly looks like.” Another executive said, “Everyone’s playing. Everyone’s making it up as they go along.”
News Summarization and Generative Search
While the publishers we interviewed said they were hesitant to put generative AI products in front of their audiences, the industry at large is keeping a watchful eye on third-party news summarization products and platforms. Generative search products that use AI to summarize one or more pages (including news articles) instead of returning links were making headlines throughout our data collection period:
- Google made AI Overviews central to its Welcome to the Gemini era presentation in May 2024;
- In June 2024, Perplexity launched a summarization product called Perplexity Pages that attracted cease-and-desist letters from publishers accusing the company of plagiarism;
- In July 2024, OpenAI announced a temporary prototype called SearchGPT, a real-time search product that would later be integrated into ChatGPT.
Since then, more AI companies — including DeepSeek and xAI’s Grok — have rolled out their own real-time search products.
A number of interviewees said they envisioned strong consumer demand for third-party news summarization products. But as one executive put it: “There is a dimension of behavioral change that’s necessary for generative search to really lift and fly.”
That change, according to one news executive, “slightly depends where the generative search is taking place. I don’t think Google introducing a generative search product into their existing search is going to particularly require a behavioral change. But it will require a behavioral change for someone to go, ‘Actually, I’m not going to use Google. I’m going to use ChatGPT search.’ There’s a bit of consumer mindset change involved here.”
To some degree, Google and Apple, in particular, could play outsized roles in driving these changes. For example, Google’s rapid integration of AI Overviews into the top of its market-dominating search engine has undoubtedly affected user expectations and behavior; AI Overviews have been rolled out to more than 100 countries since our interviews were conducted. Apple, meanwhile, currently has a lucrative deal to make Google the default search engine on its iOS mobile operating system, but has teamed up with OpenAI to power the Apple Intelligence products incorporated into iOS beginning in October 2024. (The default inclusion of Apple News on iOS and MacOS devices reportedly created 145 million monthly active readers, as of April 2024, and drove habits such as swiping for curated stories from the home screen.)
Some interviewees were prescient enough to see that search changes could be widely and quickly adopted, with far-reaching ramifications. “The thing that’s made me think everything’s going to change is I think search is going to change quite quickly,” an executive from a large international outlet said. “That worries me for lots of reasons, mainly about media plurality. The idea of AI being a single source of truth is, I think, profoundly disruptive. It’s disruptive to commercial models, and it’s disruptive in terms of democracy and choice of media sources.”
While the march toward generative search was expected to cause significant disruption, many interviewees stressed that adapting to new technology and platforms was not novel. In fact, some questioned why generative AI was afforded such attention in this regard.
An AI leader at an international broadcaster we interviewed in August 2024 told us that though generative search was something they thought about “a lot,” they felt that some of the predictions about its impact seemed hyperbolic: “We’re having industry analysts talking about 50 to 80 percent reductions in traffic within 12 months, the decimation [of traffic]. A lot of that was really unhelpful because it wasn’t founded on any understanding of the technology, or where the companies may go, or any data. It’s really unhelpful, but got a lot of traction.”
An AI leader at a major U.S. news organization suggested that publishers’ concern about adapting to the rise of generative search was partly driven by lingering resentment about having to shapeshift to match the whims of platform companies: “There’s a lot of fear [about generative search], not least because we’ve all existed in this news ecosystem for the past decade. I’ve been at [news organization] where changes that platforms make radically shift user behaviors. We were all there for Facebook traffic and then Facebook traffic went away. So I suspect the fear is not … tied to the AI piece so much as the platform and user behavior piece of it.”
For others, the most illuminating point of comparison goes back even further than the peak Facebook years in the mid-2010s. In fact, a number of interviewees argued that the emerging AI era shares most with the pre-platform era at the dawn of the 21st century.
“I think that we need to think carefully about what the media world looked like in the first decade of the web. … We were building digital audiences, but we did not really have social media yet per se,” the CEO of a local nonprofit news outlet reflected. “That’s a very illuminating decade because that is essentially what we’re going back to right now, where the social platforms, they’re just not our friends at all. We’ve already reached that post-social era, if not the post-search era. And so in this post-platform era, we have to look at that first decade.”
An executive from a global news outlet drew the same comparison. “There was a sort of period zero in publisher-platform relationships that was a period of disintermediation. It was a period where it seemed like a good deal to give your journalism to a platform and say, ‘You go ahead, you make a business model out of this and maybe send me some traffic or something.’ And it turned out that’s not a great equation.”
This comparison has been made in some reporting of contemporary deals. “Publishers want to avoid repeat of early internet era when US giants built ad-based empires using freely available content,” said a Financial Times subheadline above reporting on OpenAI’s deal with Axel Springer. According to the story, “Executives have focused for the past few months on ensuring that, unlike in the early years of the internet, Big Tech fairly compensates the media industry.”
Disintermediation
Discussing the opportunities and concerns of the current moment, an executive from a global outlet that has struck a deal with an AI company said, “Key risks, I think one word would describe it best: disintermediation.”
Put simply, this refers to the way third-party platforms can bypass news organizations, essentially cutting out the traditional intermediary between a journalist and their audience. Offering consumers condensed summaries of journalism diminishes their need to visit the original source and weakens the relationship between publisher and audience member.
Key subthemes in this regard related to:
- Brand integrity;
- Brand dilution;
- The need to double down on direct relationships with audiences.
Brand Integrity
As we noted in Chapter 2, few interviewees expected to move even their most promising audience-facing generative AI experiments into production any time soon, if ever. This caution typically arose from the view that the unreliability of the technology — particularly its propensity to generate falsehoods — is too potentially damaging to publishers’ reputations and hard-won audience trust. Related concerns about third-party products attributing inaccurate, confabulated, or otherwise harmful outputs to unsuspecting news brands featured prominently in conversations about generative search platforms, as did brand integrity concerns about adjacency to undesirable content.
On the latter, one executive at a major international outlet said, “The big concern, obviously, is around the remixing of your journalism and then the adjacency of sitting next to sources that maybe don’t have those same standards and practices that organizations with high levels of trust and high-quality methods of doing journalism have.”
The omnipresent risk of unintended, uncontrollable repercussions arguably heightens the need for strong, direct lines of communication with platform representatives. As one executive news editor at a major international outlet put it, “You’ve got to constantly be in the technology companies’ ears about this because they … are not making any of this [technology] with the use case of news in mind. Search has never been about news. … They are making these tools with the use case of connecting a person with a product or service that will then be sold, and we’re just in the mix of things that are being sought or looked for by the audience.”
Some interviewees from larger outlets said they were seeking to leverage relationships with AI companies to have input on shaping nascent generative search products. An executive from a major legacy newspaper said, “There are plenty of emerging players out there, but it feels like Google, in particular, will continue to be deeply important for at least the short- and medium-term future. We’re certainly looking at all of the what-if scenarios to [determine] how we manage through that, or change what we do, or advocate for the experiences we want to see on Google.”
Another executive from a global outlet that has held talks with AI companies without striking any deals said one thing that would “have to be baked into any [licensing] deal” was an opportunity to “participate in the forward-facing development of news products” so as to “protect … against showing up in ways that would seem to be reputationally damaging and/or damaging to user trust.” While this CEO was “relatively optimistic about certain tech partners and their interest in actually collaborating and wanting to develop products that work for users and work for partners,” they added that the dynamic is different when it comes to smaller companies that are primarily staffed by engineers, rather than by lawyers and partnerships managers.
At times, the kind of access and sway described by these interviewees has been framed as a perk of formal partnerships, such as the ones OpenAI has established with some publishers, which typically offer cash and API credits in return for access to publishers’ archives. For example, The Atlantic’s senior VP of communications, Anna Bross, told Damon Beres, a senior editor on the magazine’s technology team, “The partnership gives us a direct line and escalation process to OpenAI to communicate and address issues around hallucinations or inaccuracies.”
Describing the key components of the OpenAI deal, The Atlantic’s CEO, Nicholas Thompson, told the Verge, “[T]here is a line back and forth. So when we see something, like in browse mode we notice something interesting about the URLs and the way they’re linking out to media websites. You go back and forth and those things get fixed. So our sense is that we are helping the product evolve in a way that is good for serious journalism and good for The Atlantic.” In its rollout of ChatGPT Search, OpenAI stated that it “collaborated extensively with the news industry and carefully listened to feedback from our global publisher partners.”
Such access is, of course, beneficial to the likes of The Atlantic, although Tow Center research has found that even partners are not spared from inaccurate or “hallucinated” summaries or citations. Given that these issues also affect outlets that don’t have formal deals, questions remain about the access and responsiveness that will be afforded to news organizations outside the platforms’ privileged inner circle of “premium” partners.
Brand dilution
Interviewees also raised concerns about the scope for third-party news summarization products to dilute their brands — a concern that can be traced all the way back to our earliest report. “The biggest challenge is that all the research shows that when we become disintermediated, people don’t give the credit for that journalism or the value that they’re getting from the service to [news organization] — they give it to Google, or they give it to YouTube,” an executive news editor from a major international outlet said. “They think, ‘Oh, this is this great thing I’ve watched on YouTube.’ None of that credit goes to [news organization] and then you’re back to your business model. If you need to compel people to pay [for your journalism] because they believe you’re valuable enough to part with that money, then you are that one step removed, and again you’re degrading how you’re presenting yourself to people through that generative experience.”
Another news executive at an international outlet raised a similar concern in the context of content licensing agreements, saying, “When you license, you’re effectively giving the AI company the ability to disaggregate everything that you do, at the most microscopic level. Your brand, to a very large extent, disappears. … I can understand the short-term financial gain. But I do worry where all this leads.”
Highlighting another way in which the challenges of today — and tomorrow — drew comparisons to earlier episodes in the platform-publisher relationship, one executive said that many of the central questions around generative search would be familiar to those who have weighed the pros and cons of the Apple News ecosystem. One such question, the executive said, was: “If we’re putting our content into this ecosystem and it’s being remixed in these ways, when does it show up? How does it show up? How do we grow that audience? Basically it’s a new kind of generative SEO: How do we best connect our content to the needs of this new ecosystem so that we can serve our audience there better?”
Direct relationships only grow in importance — today and into the future
During discussions about how to prepare for a reconfigured, more disintermediated information ecosystem — one of the most recurrent themes to emerge from any aspect of our research — was that it is more important than ever for publishers to cultivate direct relationships with their audiences. This echoes a growing trend in our 2019 report, and came up in a range of contexts:
- Interviewees from outlets with strong, direct connections to their audience feel most insulated from any drop-offs in search traffic caused by generative products;
- Concurrently, generative search poses an existential threat to outlets without a strong, loyal audience;
- As we edge toward a generative search future, those direct relationships are more important and valuable than ever;
- While some interviewees said their organizations are agreeing to partner on third-party generative AI products because they want to ensure they’re reaching their audience via as many avenues as possible, others said their organizations are declining to partner if they consider them too big a threat to direct relationships with their audiences.
Once the traffic era’s vast — albeit relatively brief — influx of eyeballs had subsided, many news organizations vowed to retrain their focus on their most loyal audiences. If that was publishers doubling down on direct relationships, then our interviews suggest that some are now seeking to triple down on that strategy as the unknowns of generative search loom. That is because, if done well, generative search has the potential to give news audiences less reason to leave the third-party search environment. With that on the horizon, “You have got to accelerate everything that you are doing that is about your direct relationship with the consumer,” one executive editor at a major international outlet put it.
They continued: “We have been moving at a huge pace into signed-in users and weekly active audience being the North Star metric, because we know that you’ve got to have that route to your audience, as that is where you can re-engage and directly communicate with them, or else you’re at the mercy of a third party.”
For news organizations that can resist the short-term lure of a large check from an AI company, concerns about trading away hard-earned connections to loyal audiences are a vital factor when weighing the relative merits of entering formal partnerships or licensing deals. An executive from a large legacy outlet that has rejected the overtures of various AI companies said, “Clearly, too, what we would think good looks like [in a deal] is being able to maintain direct relationships with users. We’re not interested, at the moment at least, in becoming pure suppliers to a platform to no additional end. We are still very much in the direct relationship business.”
Uncertainty Around the Revised Value Exchange
Interviewees outlined numerous reasons for publishers to be wary of third-party generative search products:
- They are a disintermediating force that expands the distance between publishers and audiences.
- They carry threats to brand integrity and visibility over which publishers have minimal control.
- In addition to sapping traffic, they are likely to reduce the flow of audience to publishers’ owned-and-operated platforms, harming opportunities to cultivate relationships and encourage news habits; generate revenue via ads; and drive conversions of subscriptions, donations, and product sign-ups.
- Unless otherwise stated, they are being trained and improved by journalism produced by the news organizations whose audiences they are expected to cannibalize.1 While not mentioned by any of our interviewees, safety concerns and governance issues have arguably hampered OpenAI’s effort to foster the image of a reliable partner.
This raises the question: What’s in it for publishers? The topic of “value” recurred in a wide range of interconnected contexts, including:
- AI companies’ perceived failure to articulate their value proposition to news organizations, creating uncertainty over the revised value exchange;
- The absence of any value exchange when AI companies trained their LLMs on news content without notice, permission, or compensation;
- A misalignment of views between platforms and publishers over the civic and economic value of journalism;
- A misalignment of views between platforms and publishers over the value of platform traffic to news organizations.
Given the degree to which generative search platforms and products like Perplexity, ChatGPT search, and Google AI Overviews have reduced the flow of traffic to news outlets’ owned-and-operated platforms, interviewees noted that the current value exchange (crudely: traffic and/or audience in exchange for access), which has underpinned a significant proportion of the platform-publisher relationship to date, is not at all clear-cut when it comes to generative AI.
“There’s definitely a change in the value exchange,” said one CEO at a global outlet. “This idea that we would give access to our content and in exchange we would get audiences, obviously that’s now disrupted.”
Another interviewee said, “There’s some really fundamental questions about how the open internet has worked up until now and what that compact is between platforms and people who create high-quality IP.” Honing in on the value proposition part of the puzzle, they added, “If the compact was traffic, well, that no longer exists — or is likely to diminish significantly in a context where they summarize your content and munge it with many others and hold the user. The objective is clearly to hold the user within that interface, so [audiences] don’t need to go off to a third-party site in order to consume news or anything else.”
In the words of a former platform executive: “So my concern is: What is the publisher getting in this space?” This executive encouraged news organizations to block AI companies’ crawlers unless the (currently unknown) perks of access aligned with publishers’ long-term strategy and goals. “From a news publisher’s perspective, you are trying to achieve a lasting and sustainable relationship with end users. So you need to work out how and if your relationship with the AI companies will get you towards that goal.”
A policy expert at an international newspaper noted that the AI companies’ “argument falls apart in terms of how the internet economy has worked for 20 years. First, they have to come forward to explain to publishers why they should opt in to allow their content to be scraped to build these models, and as part of that, what is the value exchange they are willing to give to publishers in order to get access to the archive and to live journalism as it’s published? And that’s completely lacking at the moment from all of the major incumbents.”
That interviewee was one of a few who described negotiations over a revised value exchange as a two-step process. The first step, in this view, involves retrospective compensation for news content that has already been scraped and used to train LLMs without consent. “There’s a sense that we have copyrighted material that we invested considerable amounts of money in that has been taken and used and exploited. And there has been no value exchange. So how do you recover the very real value of what has been taken with nothing in return from a whole set of technology and AI businesses?” said one CEO at a global outlet. Another interviewee referred to this step as “fixing the leaky bucket.”
The second step centers on the establishment of suitable compensation if publishers are to provide the grounding and real-time data AI companies will need to produce timely, accurate, verified responses to queries that cannot be answered using their foundational models.
An AI leader from a global news organization summarized the major areas of contention as “a big difference of opinion in terms of what is allowable or not under copyright under different jurisdictions; a very different philosophical view about what ought to have been scraped or not and the basis on which it’s been done; and very different views from the platform operators about whether they are willing to pay a toll or admit the need for an ongoing value exchange.”
Our interviews suggest that any negotiations over a revised value exchange can be expected to rekindle longstanding tensions caused by misaligned views about journalism’s economic and civic value and how that value should be recognized.
Interviewees from the platform side offered particularly strong insights in this regard, often citing philosophical differences over the value of journalism as one of the issues at the core of the uneasy relationship between the two parties. “It’s very much not understanding each other’s position and acknowledging what is important to each other,” one former platform executive said.
An interviewee from another platform said, “Tech companies value news on revenue created for them in their businesses, which is de minimis, if not zero. News companies value it on societal impact, almost in a qualitative way and not a quantitative way. And therefore they are just not even talking about the same metrics.”
A third described how this disparity had tangible implications for their day-to-day work, as they had to be mindful of the stark contrast between how the value of journalism was conceptualized internally and externally. “It is true that news queries don’t monetize,” they said. “So the fact is, the internal conversation was always that the numbers make it fairly clear that the monetary value is de minimis, and it’s always going to be. But there’s no good way to hold that conversation externally.” Consequently, this person said, the value discussion had to be radically reframed for external audiences: “When talking to publishers and partners, it was always mission-based: News is important, [platform] users come looking for information, news is a very important class of information, and it’s fundamental to our mission to try and surface that type of response to a query. Nothing, though, which implied a certain value. Nothing like, ‘So therefore, news results represent X amount of value to [platform] or to any other platform.’ That was, of course, a conversation we always avoided, [partly] because we couldn’t really quantify it.”
Given the dominant internal view that journalism’s financial value was relatively negligible, this third interviewee concluded, “The value piece was always more mission-driven. Certainly, for those of us who’d been there a long time in the publisher partnerships world, it was always just a losing battle because no matter how much we said it mattered to [platform] — and it did — there was no check that was ever going to be big enough to solve the fundamental point of tension on all of this.”
By contrast, an interviewee who spent a number of years in a senior role at another platform before it made a sharp pivot away from news described their former colleagues’ attitude toward news — particularly those in engineering — as “something that fills a box in our product. And if these boxes are used more often than the others, then it’s useful content, and if not, then it’s not [useful], and we don’t care.’” They continued, “There is no mission. The only ones who cared about journalism and news at [platform] were the team that was dedicated to news, and to a certain extent, to be fair, a couple of people on the executive board who felt that this was important. But the general attitude is: It’s content.”
Interviewees with platform experience typically sympathized with the view that AI companies’ current value proposition, such as it is, seems heavily weighted against publishers. However, almost all suggested that too many news organizations had downplayed and/or ignored the extent to which they derived value from platforms during the traffic era, and/or made unrealistic claims about what was “owed” to them.
“The piece of this value equation that no one ever talks about is the value to publishers,” said one former platform executive. “The reason everyone has SEO departments and was doing all this kind of stuff is because that traffic has value.” The head of an AI startup whose previous work at the intersection of journalism and technology included a spell at a tech platform said that while they’ve “always been focused on the economics … the notion that if you link to something, you should be paying them in addition to the traffic you’re sending has made no logical sense in the context of the web. It felt very much like extortion.” This statement epitomizes the gulf between platforms and publishers in terms of how they value journalism. From the perspective of many publishers, of course, the platform-dominated online environment is what’s extortionary, since whatever value they might derive from fickle bursts of traffic doesn’t come close to covering the ongoing costs of a robust newsgathering operation.
A former executive of a different platform said this area required improvement as pressure mounts to find a solution to AI’s parasitic relationship to news. “There has to be an open discussion about compensation. What was always left out in the discussions about the unfair balance between the publishers and the platforms was the value that publishers get from being on the platforms. Because when we discussed all these deals in [different countries] and where we had [paid platform product] coming up, there was always this, ‘Oh, you owe us money. And our content has so much worth to you because you make so much from advertising, blah, blah, blah.’ They were never interested in actually revealing how much revenue they were making on the traffic that came from the platforms.”
Another former platform executive recalled an “extraordinary moment” during one negotiation when representatives of a news chain revealed the figure they believed was owed to them by the interviewee’s platform. This figure, the interviewee said, not only “showed how completely far apart we were,” but that the parties were “just on different planets.”2 Efforts to place a dollar figure on the lost revenue “owed” to publishers by platforms have generated much discussion, as well as methodological critiques. NiemanLab said one figure was “based on math reasoning that would be embarrassing from a bright middle schooler,” while Semafor’s Ben Smith concluded a later attempt was an “extremely aggressive, as well as pretty rough, and Swiss, estimate — but also a transparently-presented entry in a high-stakes argument.”
To avoid similar hostilities, discussions over licensing for LLMs “need to be approached in a more sensible way on both sides,” according to the first former platform executive. “What I see is almost big tech companies gaslighting publishers into believing precedents have been set, deals have been done, and benchmarks are there. … It doesn’t have to be that way,” they said. “Collaboration [between publishers] is the leverage point, but they need to do it in a sustainable way and not have unbelievable, ridiculous, grandiose views on this.”
Elsewhere, we did hear cautious optimism that technology companies’ perceived inability to view value through any prism other than their bottom lines may be a factor in improving relations. While acknowledging a raft of caveats, one of the former platform executives said, “I’m partly optimistic platforms and publishers can get back together, and hopefully in a better way than we did in the past, as there’s now a different need for the content that publishers have to offer. … And it actually has a distinguishable value to the future business model of AI.”
Traffic
As noted earlier in the chapter, a key change to tech companies’ value proposition is the expectation, now largely fulfilled, that advances in generative AI will further diminish the flow of traffic from platforms to sites owned and operated by news outlets. Accordingly, interviewees often framed their level of concern about the knock-on effects of generative search through the prism of their outlet’s current reliance on search traffic.
At one end of the scale, an executive at a digitally native outlet said, “If our Google referrals were to decline significantly tomorrow, it would cost us something like five or six percent of our overall revenue. It would be infuriating, and let me tell you, I don’t want to have to find another five percent from somewhere else. But it’s an existential threat for a lot of other places, and it’s not an existential threat to us.”
By contrast, an executive at a legacy outlet said, “This is a major crisis, right? We have seen search referrals drop year over year. We’re seeing referrals from all sources falling. And so it is the real challenge of trying to figure out how do we actually find and engage audiences?”
At times, interviewees cited broad metrics as an indication of what they stood to lose. A digital editor at an international outlet said, “I’m worried about what it’ll do to our traffic because, quite seriously, we can get about 50 percent of our traffic from search.” Describing a similar reliance on search traffic, an editor from an international local news chain said, “In about 2018, somewhere in the region of 60 to 70 percent of traffic to our sites was internal traffic. Now that’s shifted to about 20 percent, and about 55 percent of traffic for [local title] is coming from Google. So Google is absolutely huge to us as a business. In other [local titles in the chain], Google traffic can go up to about 60 or 70 percent.”
This interviewee said their chain’s dependence on Google traffic was a source of consternation and a warning sign about the rise of generative search. “By shifting all of our direct traffic to them through news aggregators [Google News, Chrome Suggestions] and Discover, Google were very, very clever,” they said. “It’s the whole thing with the frog, and turning up the water by one degree, and then the frog doesn’t realize it’s being boiled. They were very, very good at implementing that news aggregator technology and taking out the direct traffic. And people see it as a good thing: Google traffic was going up. I think they’ve misstepped on generative. They’ve gone too far too quickly. And I think it’s awoken a lot of people to actually how bad this is going to be in the long run. We’re the providers of information and we want to be the distributors. But Google now wants to be the distributor.”
While the hit to traditional search traffic is a concern for many, disrupting Google’s stranglehold on the search market could break a cycle of dependence stretching back decades. “Something like 25 to 30 percent of our traffic comes from search,” an executive at an international, subscription-based outlet said. “That is a huge dependency on a supplier on any level. There’s no other part of our business that hinges on one supplier in quite the same way. Yet there is absolutely no contractual relationship that underpins that whatsoever. If you think about it, that’s quite mad, right? If someone said, ‘I’ll be your paper supplier, I’ll supply 30 percent of your paper or 30 percent of your workforce, but we don’t have a contract, we’ll just kind of do it on a handshake that didn’t even really happen,’ you’d say, ‘Of course not. That’s insane. Why would I do that?’ So I think once bitten, heavily, on behalf of the publishing community, we’re all thinking we’re not going to get bitten twice.”
While Google was front-of-mind for most interviewees in this context, an executive news editor from an international outlet noted that, while their team had done a range of tests to model the potential implications of generative search swallowing a large portion of their traffic, they were “already dealing with really different types of search experiences,” as search “more generally is radically changing” because “we know that the vast majority of people under a certain age will turn to Instagram and TikTok and search there before they will use Google.” Indeed, an April 2024 survey by Forbes Advisor and Talker Research of 2,000 Americans found that 45 percent of Gen Z and 35 percent of millennials are more likely to use “social searching” on TikTok and Instagram over Google.
An executive from a global subscription-based outlet agreed that while nobody could precisely predict the downstream impact on search traffic, their five-year plan included modeling declines ranging from 5 to 30 percent. The benefit of this “war-gaming,” as they termed it, was that it allowed them to plan ahead for the downstream impact on their outlet’s audience, revenue, and discovery: “OK, well, if it’s 30 [percent decline], what will we need to have done on our end to ensure that we’re a destination site, to drive subscription repeats, to drive more engagement on the site? What are we going to do about that?”
Google Zero is the term coined by The Verge’s Nilay Patel for the “moment when Google Search simply stops sending traffic outside of its search engine to third-party websites.” Interviewing Meredith Kopit Levien, CEO of The New York Times, in 2023, Patel said, “I’ve lived through Yahoo going away; I’ve lived through Facebook going away; I’ve lived through a very strange moment of Snapchat going away. I feel like we would be making a mistake if we didn’t envision what it would look like if Google went away.” During our interviews we heard examples of something tantamount to Google Zero being preached internally, so widespread was the belief that generative search platforms would throttle that particular audience tap. An audience executive described how senior leadership at their outlet had been “pretty clear in basically saying search is going to zero for news organizations.” The message from the top of their organization, they said, was, “social is going to zero. SEO is going to zero. Don’t rely on any of that.”
In the short term, this creates a disparity between senior leaders who are “so far in the future” and today’s “practical reality [which] is that [news organization] is incredibly buoyed by search at the moment.” As of summer 2024, “search traffic continues to go up and it’s an increasingly big part of our traffic,” they said.
A positive effect of this approach is that it both eliminates the need to war-game potential traffic-loss scenarios and insulates the outlet from the stress of waiting for the severity to come into focus. As this interviewee said, “We might see a drop in search traffic, but because of what [senior leadership] is saying, it really doesn’t matter at the end of the day. We’re not banking a future for search in any capacity. We’re counting on it being zero. So anything that is above zero is really gravy.”
On the flip side, with audience management and SEO very much part of the mix for many today, this focus on a rapidly different tomorrow can create internal management issues. “I literally run these things. You can’t go around telling people they’re going to zero. I have to work with people and tell them that it’s not going to zero [yet] and that they should care about [traffic] today,” the audience executive said.
This strategy of treating search traffic as a nice-to-have rather than a need-to-have resonated with other interviewees, many of whom had dealt with the aftermath of traffic taps abruptly drying up during the social era. Musing on the idea of adopting a Google Zero mindset, an executive from a global outlet said, “In some senses, it’s a kind of back to basics. It’s an unhooking from an ecosystem which has proven to be a fairly fickle friend.”
Another thoughtful perspective on a Google Zero-esque scenario came from a nonprofit news executive who had previously held senior roles at for-profit outlets:
In every role that I’ve had this century, there was always a tension where, if we were looking to engage audiences on, say, Facebook, we’re figuring out how we drive people from there back to [the website] where we have ads on pages and can make money, or where we drive subscriptions and can make money. I’m in an organization now where that’s not a thing. It’s a nonprofit news organization, so impact is the goal, not budget. There’s a freedom to that because it’s possible that as long as we’re able to track that impact, it’s possible that a partnership where there’s no traffic being driven back to [our website] could be fine. I would want to be really cautious about what the impact of feeding [news organization’s] content into an LLM could have on the organization, but on the other hand if there is the potential for wide impact, then a thing that would be a drawback in my old life but not in this current one — no driving of traffic — might not be a bad trade-off.
Other interviewees were less convinced by this approach — even if AI companies are ultimately forthcoming with suitably detailed audience metrics, which is far from a given. Drawing on lessons from earlier periods in the platform-publisher relationship, an executive news editor at an international public service outlet said, “For organizations whose primary objective is straight-up impact and awareness of a story or subject, in five years you’ll again just be rebuilding yourself somewhere else. It all comes back to using these platforms … to enhance your reach and find the people that you don’t find that often, but you cannot build your businesses or projects on these platforms because it will just be pulled out from under you at some point.”
The peril of trying to build a business on top of third-party platforms was demonstrated during the social era by the likes of Mic and LittleThings, both of which closed in 2018. “[I]f you live by the sword you die by the sword,” as one Mic investor put it at the time. “Facebook drove our ascent, when they started to prioritize outside links and later video, and also our decline, when they changed their feed algorithms, and canceled our show.”
Indeed, the reputational risks attached to putting too many eggs in the basket of a third party’s generative product are stark. As the nonprofit executive quoted above warned: “If generative AI comes in and garbles the message or, even worse, creates something that’s factually inaccurate, then that’s the opposite of what an organization like [news outlet] wants to do. [Outlet] is looking to provide coverage of underserved areas to the populations in these underserved areas, and particularly in areas where disinformation is rife and access to truthful information has been shut down. If there’s potentially a train we could hop on that gets us there more efficiently, then I can see a scenario where we’re all for it — but only as long as there’s some way that I can track that it’s happened.”
Blocking Crawlers
Publishers have the option to block AI companies’ crawlers via the Robots Exclusion Protocol (robots.txt). As of May 2025, 32 percent of the top 50 news websites in the United States were blocking OpenAI’s search crawler, 40 percent were blocking its user agent crawler, and 50 percent were blocking the crawler that collects content used to train its generative AI foundation models. Fifty-six percent were blocking Perplexity’s crawler, 58 percent were blocking the crawler behind Google’s Gemini, and an average of 60 percent were blocking Anthropic’s crawlers. Among those that have been reluctant to block, the possibility — or expectation — that these platforms will ultimately replace search is enough to prevent them from taking steps that might preclude them from reaping potential future benefits.
Among advocates of blocking crawlers, an AI leader at an international local news chain looked beyond their outlets’ current dependence on search traffic and said, “What it means for us, in terms of preparation [for the next generation of search products], is lockdown. And I’d say this to any other publisher: Lock down what’s valuable to you. Probably what you’ve already given to Google is gone. But if you are a newspaper like us, we have information going back for [hundreds of] years. Lock it down. Don’t give it to Google. Use the technology to build something similar to Google, but on your own platforms, and monetize it.”
Similarly, an editor at a international digital native outlet that also gets a considerable amount of search traffic said, “Like a lot of publishers, we’re blocking user agents from ChatGPT, Google, and others to stop them ingesting our content, and I’ve got a conversation later today, actually, about creating a proprietary search chatbot based on our archive.” The decision to block, they said, was driven by “skepticism and the uncertainty over what a third party would do with the data once they’ve got it.”
A former platform executive suggested that blocking should be publishers’ first line of defense when planning for the expected decline in search traffic from the transition to generative search. Having argued that publishers typically didn’t block search engines because the resultant traffic had some value for them, the former executive said, “In the age of AI, it’s not clear and direct to me what publishers get [from generative search].” This person argued that the fetishization of traffic was a defining strategic error of the traffic and social eras that made even less sense in the nascent AI era. “It’s not the end goal,” they said. “It’s a means” by which a news outlet can forge a direct connection with its audience.
The blocking of AI companies’ crawlers is not without challenges. Some AI companies apparently crawled web pages before making website owners aware there were crawlers to block. OpenAI announced its GPTBot web crawler could be blocked in August 2023 — nine months after the release of ChatGPT — while Apple’s paper on its Apple Intelligence Foundation Language Models (AFM), published in July 2024, stated that the “AFM pre-training dataset consists of a diverse and high quality data mixture [including] data we have licensed from publishers, curated publicly available or open-sourced datasets, and publicly available information crawled by our web-crawler, Applebot.”
What’s more, the mechanism through which blocking is facilitated, the Robots Exclusion Protocol is seen as something of a blunt tool and easily circumvented. Tow Center research published in March 2025 found that several major AI companies’ crawlers appeared to be accessing content from publishers who had blocked their crawlers; Digiday reporting from April 2025 also found that referral traffic from AI chatbots or search platforms is growing even to sites that are attempting to block platforms’ crawlers. “The regulations that underpin how the internet works are being completely challenged by this technology, and these [same tech] companies are in charge of designing how those protocols work,” one policy expert said.
“Google and Microsoft made noises to suggest that they were thinking about how to update robots.txt to empower publishers to be in control of their own destiny. Neither have really moved satisfactorily to do that and we’re still in a position of limbo where all we’re relying on is a protocol that was designed 20, 25 years ago, which is not compulsory, which is not granular in any way, which provides very little optionality in terms of what you will allow your content to be crawled for or not.”
Flaws in the existing system have already generated headlines — and litigation. For example, in June 2024, research by developer Robb Knight and Wired found that Perplexity was able to summarize pages from which its crawler was supposed to be prohibited, suggesting the company’s crawler was not honoring robots.txt — and two days later, Wired reported that Perplexity Pages had plagiarized its piece on the company’s plagiarism. Perplexity co-founder and CEO Aravind Srinivas told FastCompany that pages blocking the company’s crawler could still find their way to Perplexity via an unspecified crawler that was not blocked. “Perplexity is not ignoring the Robot Exclusions Protocol and then lying about it. … We don’t just rely on our own web crawlers, we rely on third-party web crawlers as well,” Srinivas said.
On July 22, 2024, Wired’s parent company, Condé Nast, followed Forbes in sending a cease-and-desist letter to Perplexity, accusing the company of plagiarism and demanding the removal of Condé Nast material from its search results. The following week, Perplexity announced its Publishers’ Program — which includes revenue-sharing agreements, API access, and a year of Enterprise Pro access, as well as access to data analytics to track trends and content performance.
Audience Data
A number of interviewees noted that for publishers to navigate their disintermediated future, they would need far better access to more audience data from GenAI companies, a historic sticking point in the platform-publisher relationship. At least one interviewee even suggested that publishers should band together to establish minimum standards and use those data demands as leverage when negotiating licensing agreements.
“If you’re signing up to an agreement with an AI company now in this phase, having data on usage, uptake, the appearance of your journalism in outputs will be critical to understanding the impact of these technologies on existing audiences and … being able to make calculation of what the value of your journalism is to that business,” said one. “There’s a very significant need for that sort of data.”
To some extent, wrangling over data can be boiled down to an age-old question: Who owns the audience? Here, too, interviewees turned to the recent past for insights. Some, for example, pointed to Apple’s handling of subscriptions made through Apple News. The tech giant’s vaunted commitment to privacy meant publishers could not access subscriber data such as email addresses that would be vital to cultivating a direct relationship. “For sure, it’s an Apple customer, but they’re subscribing to your product, so you should be entitled to get access to more information,” said one former news executive at an international outlet. This person went on to argue that Subscribe with Google had struck a better — albeit imperfect — balance in terms of giving publishers a shot at developing a direct relationship without compromising customer privacy.
Multiple interviewees said the walled gardens of generative search platforms meant their desire for high-quality audience data would be stronger than ever, noting that there was little precedent for sharing: “In the past it’s been very, very hard to get data from platforms around how news is performing [there],” said one.
An executive from a global outlet that has signed deals with AI companies outlined some of the “relatively granular” audience data they would eventually want and said their tech partners had indicated an openness to meeting their demands. However, they added, “I don’t think I’ve ever had a satisfactory level of data back from any technology company. It’s always been kind of least worst. So my expectations are quite low.” Pointing to another distinction between news organizations and tech companies (see Chapter 5), they added, “My expectations are low because it’s usually the last thing on the engineering team at the technology company’s mind.”
To date, Google has only established one formal news partnership akin to OpenAI’s — in January 2025, with the Associated Press — and some publishers have already expressed discontent about the inadequacies of available data since the rollout of AI Overviews. As The Washington Post’s deputy head of audience strategy, Bryan Flaherty, told NiemanLab, “There is … no data provided by Google around AI Overviews — what search queries these show up on, what traffic is driven by AI Overviews links vs. other features, etc. — which makes it difficult for publishers to assess performance and make strategy decisions.”
Among the quantitative data points cited as ideal — if unlikely — were:
- The number of times an outlet was cited in a response;
- The topics about which an outlet’s content was used to generate answers;
- The number of times an outlet’s content was interrogated but not cited;
- The click-through rate for citations;
- The extent to which snippet length affects click-through rate;
- The extent to which the style and appearance of citations affects click-throughs.
Other, more qualitative questions that would require independent research include:
- Who do audiences credit for the information they are served through these platforms, and how are those associations formed?
- What are the processes through which audiences form those associations?
- When, why, and how do audiences make decisions to pursue further details on a response?
- What factors drive audiences to seek — and settle for — answers via generative search as opposed to primary news sources?
- To what extent do audiences attribute positive and negative aspects of AI-generated responses (e.g. depth, clarity, and quality vs. inaccuracies, incompleteness, and uncertainties) to AI companies versus the news brands cited, and how are those associations formed?
- What factors motivate audiences to continue, reduce, or increase their direct engagement with news brands’ owned-and-operated properties if and/or when generative search platforms are established?
- To what extent do the above questions differ from one platform to the next?
Licensing Deals
One key way that AI companies have sought to formalize their use of news content — albeit involving only a sliver of what has already been scraped — is through individual licensing deals or revenue-sharing agreements.
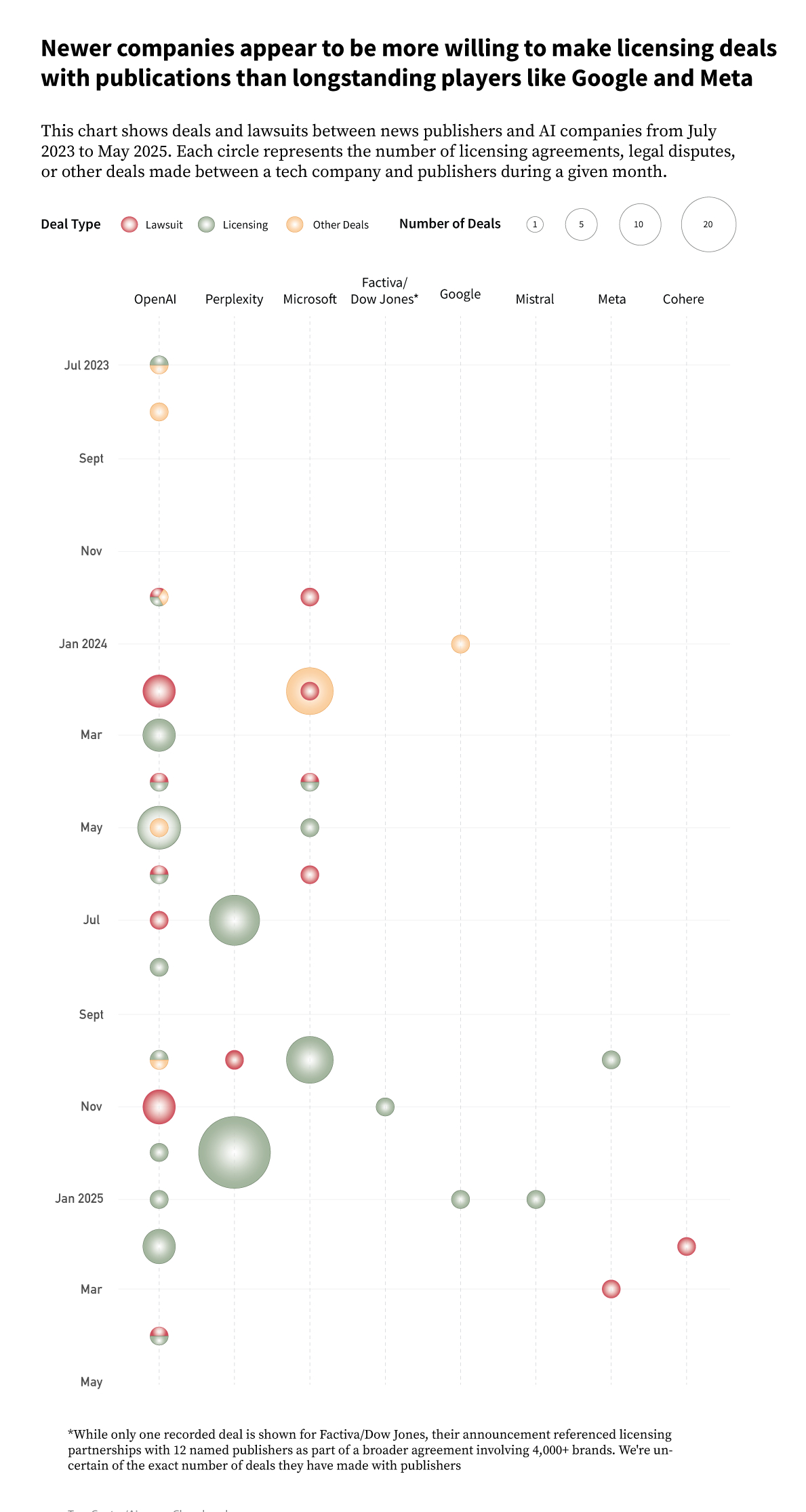
In July 2023, the Associated Press became the first news publisher to enter a content licensing agreement with OpenAI. Between then and May 2025, 16 other publishers have made deals with the company, including Hearst, Condé Nast, Axel Springer, and News Corp. In 2024, Perplexity also announced 22 revenue-sharing agreements through its Publishers’ Program, including TIME, Lee Enterprises, and Der Spiegel; Dow Jones announced that it had secured AI licensing deals with nearly 4,000 global sources for its Factiva Smart Summary research tool; and Microsoft signed content licensing deals with Reuters, Axel Springer, Hearst Magazines, USA Today Network, and the Financial Times to appear in Copilot Daily, which provides users with a spoken summary of the weather and current events. Meta and Google have so far each only signed one AI deal with a news publisher — Reuters and the Associated Press, respectively. In January 2025, the French AI company Mistral signed a deal with global news agency Agence France-Presse (AFP) to make its articles available to its chatbot.
As of May 2025, there have also been nine copyright infringement lawsuits filed against OpenAI (four of which also targeted Microsoft), by news publishers from the U.S., U.K., Canada, and India; one filed against Perplexity by the Wall Street Journal and the New York Post; one filed against Meta by French publishers and authors; and an industry lawsuit by the News/Media Alliance against Canadian AI company Cohere. In February 2025, Thomson Reuters won the first major AI copyright case in the U.S. against legal AI startup Ross Intelligence, with the judge ruling that Thomson Reuters’ copyright was infringed when Ross Intelligence reproduced materials from its legal research firm Westlaw.
Training, grounding, and real-time data
News content can be used in LLMs as training data to help build models; as grounding data to enhance a model’s foundational knowledge (e.g. news articles published after the model’s initial training); and as a source of real-time data to provide immediate, up-to-date grounding about current events.
For instance, OpenAI’s first major licensing agreement, with the Associated Press, gave the company two years’ access to the AP’s post-1985 text archive. This deal covered training data and grounding data, according to The Washington Post, which reported that the “AP deal gives OpenAI access only to its archive, but the archive is updated with recent news stories regularly.”
Subsequent deals included real-time data, beginning with OpenAI’s December 2023 agreement with Axel Springer. Described by Axel Springer CEO Mathias Döpfner as “the first of its kind,” the partnership “will help provide people with new ways to access quality, real-time news content through our AI tools,” OpenAI COO Brad Lightcap said. In addition to a one-off fee for archive access to train new models, OpenAI pays Axel Springer “a recurring income stream from the use of new content” and “‘kickers’ — in effect extra payments — for popular content, meaning the media group will be paid more each time its articles are used by AI,” according to the Financial Times.
The FT report described Axel Springer’s agreement with OpenAI as a “landmark content licensing deal” that “marks a breakthrough in the media industry’s efforts to secure its commercial future as artificial intelligence technology takes its next generational leap.” Below a headline stating that the partnership “sets [a] new template for media ties with Big Tech,” reporters Daniel Thomas and Madhumita Murgia wrote that the “deal is being scrutinised by rival publishers as a potential road map for how the relationship might work in the future.”
Statements about OpenAI’s subsequent agreements often echoed the Axel Springer deal by referencing the inclusion of real-time data as well as archive access for model training. March 2024 deals with Le Monde and Prisa Media were said to “enable ChatGPT users to engage with … high-quality content on recent events in ChatGPT”; the FT deal, announced in April 2024, was said to “enrich the ChatGPT experience with real-time, world-class journalism for millions of people around the world”; and The Atlantic stated in May that its “articles will be discoverable within OpenAI’s products, including ChatGPT,” and “The Atlantic will help to shape how news is surfaced and presented in future real-time discovery products.” Other statements, such as News Corp’s, did not explicitly reference real-time data, instead focusing on its reputation for trusted content: “OpenAI has permission to display content from News Corp mastheads … with the ultimate objective of providing people the ability to make informed choices based on reliable information and news sources.” Similarly, Hearst Newspapers president Jeff Johnson said its agreement “allows the trustworthy and curated content … to be part of OpenAI’s products like ChatGPT — creating more timely and relevant results” (emphasis ours), while Condé Nast CEO Roger Lynch said its deal means “the public can receive reliable information and news through [OpenAI’s] platforms.”
The licensing deals have also laid the groundwork for a rash of lawsuits from news organizations challenging AI companies’ unsanctioned use of their reporting and analysis. OpenAI’s use of news content without permission or compensation is central to the litigation brought by the likes of the New York Times and Tribune Publishing. In an OpenAI post addressing the Times’ lawsuit, titled “OpenAI and journalism,” the company argued: “Training is fair use, but we provide an opt-out because it’s the right thing to do.” Yet such opt-outs (blocking the company’s crawlers via the Robots Exclusion Protocol) were only made available long after earlier models had been built.
In light of this, it is noteworthy that some of OpenAI’s announcements about licensing deals have explicitly stated that use of news partners’ content for model training forms part of the paid arrangement. For example, announcing its December 2023 deal with Axel Springer, OpenAI stated, “The collaboration … involves the use of quality content from Axel Springer media brands for advancing the training of OpenAI’s sophisticated large language models.” Likewise, the announcement of the deal with Le Monde and Prisa Media, in March 2024, said the pair’s “content will … contribute to the training of our models.”
Although training of future models was not explicitly mentioned in OpenAI’s announcement about its deal with The Atlantic, the magazine’s editor-in-chief, Nick Thompson, told the Verge that OpenAI is only permitted to train models on Atlantic stories for two years. Once the deal expires, “they are destroying our data. … They train each new model on entirely new data, and so they will have our data for the next two years, but when it gets to GPT6 they won’t, unless they have another deal.”
If the above statements are read as an admission that news organizations should be compensated when their content is used to train LLMs, they would seem to expose OpenAI and other AI companies to claims that they owe retrospective compensation for content used to train earlier models. Such language appears to set a precedent for compensating news organizations when their content is used to train future models. Alternatively, the statements could be read as an admission that AI companies are using licensing deals to pick winners by funneling money to a handful of powerful incumbents, while leaving scraps for the rest.
Is it a good deal?
Interviewees’ perspectives on these deals ran the gamut. At one end of the spectrum, we heard that AI companies were exploitatively preying on the news industry’s precarious financial position. At the other was the sentiment that these deals could amount to “free money” that could be funneled into doing good journalism. In between, the most common sentiments were exasperation at the lack of transparency about the terms of AI-publisher deals and unease at the lack of information about the mid- to long-term implications of allowing AI companies to develop their models using news content. “The devil is in the details,” as one executive put it.
Putting aside other aspects of these arrangements, multiple interviewees argued that one positive aspect of the early licensing deals was that they helped establish a precedent that journalism has value to AI companies and therefore must be paid for.
“Setting the principle that the journalism that’s used to build, ground, and train these products has value, and that real money should change hands — as it’s changed hands for commercial licensing deals for journalism and use of IP for many, many years — I think getting it on record and in the public domain that this is normal and should happen is very, very good,” said an executive from a major global outlet that had discussed licensing deals without reaching any agreements.
A technologist from an outlet whose owner had signed a licensing deal argued that the AI era has been distinguished by a tacit acknowledgement that journalism has financial value. “The thing I like about the licensing deals is that they essentially say your content has intrinsic value. It has at least enough value that it’s worth paying for, which I think is different to search and even social because those did not require either of those groups to have an intrinsic belief in the value of the content, right? I think this is actually a very good thing for publishers, the identification that their content is valued.”
Perhaps the bluntest assessment came from an executive at a global outlet that had struck licensing deals: “We have some principles from period zero” of the platform/publisher relationship, including that “we want our journalism respected. … People should pay for stuff they want to use. That’s what I think about licensing.”
But beyond their relief that licensing deals signal journalism’s financial value, interviewees articulated a wide range of views on these arrangements. Some interviewees — most commonly those from larger outlets with diverse revenue streams and/or solid subscriber bases — took a fairly casual view of the current deals, framing them as ancillary, additive income that carried minimal risk. “From a business perspective, signing contracts with platforms, as some have already started to do, opens up a new business line to diversify your revenue streams,” a former executive of a large international news organization said. Perhaps the most relaxed assessment we heard came from an executive at a global outlet that had struck a deal, who said it “feels like quite a good, constructive relationship with what could be a really interesting company. They might be here in 24, 36 months, they might not be.”
Another recurring theme was that one-off payments amounted to AI companies exploitatively preying on the news industry’s precarious financial position to enrich themselves. Interviewees approaching the subject from this perspective tended to be sympathetic to the notion that cash-strapped news organizations might feel compelled to take money, but also concerned that the longer-term implications are overlooked or unknown.
“This is a really scary moment for journalism,” a digital editor at an international outlet said of the wave of licensing deals. “Everyone can suddenly see there’s a huge amount of money on the table. Journalism’s in a really bad way. So you just take the money now and don’t ask questions. But really, long term, you need something to protect the reputation of the publication and also the value of that content.” An executive news editor from a global news outlet said, “We’re in the space of this being one of the great gambles of modern times when it comes to the deals and decisions about the future of our industry.” Elsewhere, an AI leader from an international local news chain described licensing deals as AI companies exposing their disdain for journalists and journalism by “turning us into fact finders.” (Julia Angwin, founder of Proof News and co-founder of The Markup, raised a similar point at a Columbia Journalism School event in October 2024, noting, “There’s a hope for journalism, but it’s also a sad hope: that we’re just low-paid fact-checkers for Big Tech.”)
An AI leader from an international public service news organization summed up the mood this way:
The problem is you’ve got a print and news ecology that is structurally stressed, it’s financially constrained. And you’ve got these large companies showering cash around. So everyone’s terrified of being left out. And if you can grab 10 million, or whatever the right number is, and add it to your account and look like a digital pioneer, then it’s kind of understandable. But where does all this lead?
Drawing on the past
Most interviewees had not been privy to negotiations around licensing deals, so they drew on their past experiences navigating paid partnerships with technology companies, including incentives to use proprietary publishing formats like Facebook Instant Articles and Facebook Live and direct payments for participating in Facebook News and Google Showcase. One key lesson mentioned by multiple interviewees was that any check is best viewed as a one-off, even if the initial pitch implies it is part of a long-term commitment to support journalism. For example, one CEO at a global outlet said that by the time Facebook News tab deals arrived in 2019, they were under no illusions that the agreements would yield a reliable revenue stream: “We definitely viewed the Facebook deal as transactional and almost certainly transitory. So we never expected the Facebook deal, particularly, to renew.”
Earlier deals had led some to conclude that even one-off, short-term financial infusions from tech companies can create brand-building opportunities that cannot be rejected out of hand, but depend on what is being traded away. “At the end of the day, if you’ve signed a deal and gotten a million dollars and that’s going to pay the salaries of your journalists,” it might be worth doing, one executive said. “I think it depends partially on what you’re giving up and what you’re committing.”
This interviewee, who was previously at an outlet that signed a Facebook News tab deal, said, “Facebook News was a big nothing. Nobody ever went to the tab. It wasn’t used. But for publishers that got money from that, that was real money that funded journalism, that funded your own technology, that funded other things. So that stuff is not the kind of thing that we can be cavalier about or dismissive of.”
While acknowledging that a licensing deal with an AI company would likely introduce many additional caveats, they went on to articulate why a viable case could be made for accepting a check as long as the deal was signed with eyes open and with the understanding that such funding can only be one slice in a diverse revenue pie: “I would like to understand what’s in those [contracts], so we can think more clearly about where our risks and opportunities are. … [But] if it’s just free money and all you’re giving up is your brand association, then I could use a million dollars. I could use that to funnel into the development work, into the journalism that we need to do. Maybe I’m too much of a realist, but I think that’s been the name of the game. As our industry has been in turmoil, we have to continue to look for various revenue sources. Can any one of those be our future now? Would I recommend that we have a strategy that’s only AI-oriented? No. But if we can find a million dollars here or there, I’d certainly be willing to take it.”
Other interviewees acknowledged that while the industry’s precarious financial position may tempt some publishers to take whatever cash is on the table, they felt confident in their ability to make a more clear-eyed assessment this time around. For example, one executive with experience in both journalism and the tech industry said, “Undeniably the news industry has a lot more skepticism around these deals than they did up to 2017, 2018. We’ve been burned a few times, so we’ll take the money and run, but we know we’re taking the money and running as opposed to thinking Instant Articles may become the next thing.”
This executive, who worked for an organization whose owner has a licensing deal, made the outlier argument that the current wave of licensing deals carries less risk than those of the past because they are not premised on tech companies controlling access to audience and traffic:
These deals are being, I think rightly, read through the lens of new business development. This could be a potential source of business income as opposed to audience development. I think that’s the major distinction from, say, 2014 to 2017, and the implicit or sometimes explicit promise of “Partner with us on this because you could 10X your audience,” “Partner with us on this because we have the top of the funnel and therefore you will grow,” and so on. That matched the mood of the moment. But I don’t think anyone is looking at these deals and saying that this is a scale play. They’re looking at it as money in hand to feed into our operational costs and give us runway. I don’t think any publisher is looking at these deals with OpenAI and saying, “Oh my God, we’re going to 10X the flyby users who come to our site.” I think that’s the distinction and it’s in a good direction where it’s not carrying as much risk.
Others, however, were less optimistic that past lessons have been absorbed, and expressed concerns that the implications could cut far deeper than previous dalliances with Big Tech.
“Right now, these licensing deals are cherries on top of an ice cream,” said one person with experience on both sides of the divide. “It’s like, ‘I don’t have to do anything different for this. It’s just extra money that someone is giving me.’ That’s fine. But let’s say we’re sitting here five, eight years from now, and the predominant way in which people interact with the online world is through their own AI agent. What happens when you’ve only got the cherry, and the rest of the ice cream and the cone and everything else is gone? Is that going to feel like it’s a sustainable model? I don’t know. I don’t think so.”
One interviewee who leads an AI startup shared a particularly bleak vision of a potential future wherein, rather than reporting and writing stories that live on user-facing websites, the job of journalists would primarily be to collect facts and enter them into a database that AI search tools would reference to produce bespoke stories for users, replacing the need for human-written stories. “You would just have people working to create information that would go into the best vector database of this stuff. That’s one vision. I don’t think it’s a particularly pretty vision. … But that’s the kind of thing that if you just play the tape forward for AI, native, becoming the interface, at least it still makes sense.”
For some, past experience has led to greater self-awareness. “I get a bit concerned about for-profit news organizations because wow, our track record’s not been good at looking out for ourselves in those kinds of deals,” said one executive, adding that they were “seeing a lot of things that are really familiar” in the industry’s current wrangling with AI companies. They compared OpenAI’s pitch to publishers to that of Facebook Instant Articles, but said it was far worse because, beyond acting as an intermediary, AI companies are transforming journalists’ work. “This is actually that plus tax, in the sense that it’s not just ‘Take my content and put it on your platform,’ but ‘Take my content, put it on your platform, and now generate something new based on it,’ which is really just taking that up a notch. So I have concern that, as we did in the past, we might be taking some short-term steps without paying close enough attention to their long-term ramifications.”
While earlier scale plays ultimately led to a renewed focus on publishers’ owned-and-operated platforms and diversification of revenue streams for surviving outlets, this person warned that ignoring long-term priorities could lead to an even starker outcome: “We are not just improving a space that we don’t own when it comes to generative AI and these deals, but we are also training bots how to do the kind of improving that we do, so not only would we lose the improvements, but we might lose our entire business out of it. So there’s a lot more risk this time around.”
At the time of our interviews, most content deals involved OpenAI; high-profile deals between the company and News Corp, Vox Media, The Atlantic, and Condé Nast were announced during this data collection period. These deals, which typically appear to involve a mix of cash payments, credits, and access to technology in exchange for access to publishers’ archives and two or more years of forthcoming news content for retrieval-augmented generation, were the main frame of reference for interviewees when discussing licensing deals.
With ongoing litigation and calls for regulation looming, some of the more cynical assessments have drawn on the past when questioning AI companies’ motivations for pursuing deals with influential publishers. Such critiques have at times been published by outlets that have entered into deals with AI companies. The Atlantic’s announcement on May 29, 2024, of its deal with OpenAI, for instance, was sandwiched between two articles by its own journalists that were highly critical of news organizations willing to strike such deals. The first, titled “Media Companies Are Making a Huge Mistake With AI: News organizations rushing to absolve AI companies of theft are acting against their own interests,” was authored by Jessica Lessin, founder of The Information, and published a week before the announcement. The second, “A Devil’s Bargain With OpenAI: Publishers including The Atlantic are signing deals with the AI giant. Where does this lead?” was penned by Damon Beres, the magazine’s senior tech editor, and appeared just hours after the deal was announced.
“That media companies would rush to do these deals after being so burned by their tech deals of the past is extraordinarily distressing,” Lessin wrote. “And these AI partnerships are far worse for publishers. Ten years ago, it was at least plausible to believe that tech companies would become serious about distributing news to consumers.”
News organizations following the likes of Axel Springer, the Financial Times, and, within a week, The Atlantic, into such partnerships were complicit in accelerating the downfall of a business already “entering a death spiral,” Lessin argued.
And now, facing the threat of lawsuits, [AI companies] are pursuing business deals to absolve them of the theft. These deals amount to settling without litigation. The publishers willing to roll over this way aren’t just failing to defend their own intellectual property — they are also trading their own hard-earned credibility for a little cash from the companies that are simultaneously undervaluing them and building products quite clearly intended to replace them.
Lessin’s skepticism of AI companies’ motives was echoed by the union representing staff at The Atlantic, which said it was “alarmed” by the agreement and demanded that management make the terms of the deal public “immediately” and “without spin.” Two months later, dozens of Atlantic journalists signed a letter calling on their employer to “stop prioritizing its bottom line and champion the Atlantic’s journalism” and demanding that management include AI protections in their union contract. In a piece titled “Generative AI Can’t Cite Its Sources: How will OpenAI keep its promise to media companies?” Atlantic staff writer Matteo Wong argued that “what these media partnerships have been all along [is] tech companies paying to preempt legal battles and bad PR, [and] media companies hedging their bets against a future technology that could ruin their current business model.”
Such criticism recurred across our interviews. “It’s obvious to most people that these deals are no-sue deals,” said one former platform executive, pointing to the rate at which OpenAI deals accelerated after the Times filed its lawsuit in December 2023. “These are not product and licensing deals. … These are ‘make-this-problem-go-away’ deals, which, by the way, there is history of in the era of traffic.” (OpenAI struck two deals prior to the Times’ complaint and 15 deals in the 16 months since.) Referencing the copyright case Agence France-Presse brought against Google in 2005 before settling with a licensing agreement in 2007, the former platform executive said, “Even before Google Showcase, there were a lot of complaints from the news agencies. … The news agencies were yelling at Google and Google did some deals to just make the noise go down. They dressed it up with some product stuff around it, but it was all bullshit.” Another former platform employee posited that “Google News Showcase deals are 1000 percent hedging against regulation,” suggesting that the choice of countries and sequencing of deals are “a one-to-one match” with places where “the fires were hotter.” Google “launched Showcase to essentially channel a new revenue stream to publishers who they would rely upon to dial down heat for passing regulations.”
An executive at an outlet whose owner had struck a deal suggested that the same playbook may be in use again. “Candidly, it would be great if we didn’t sue them, right? That’s a small thing, but that’s the kind of thing that’s an existential threat to a company like this, right?” they said. “If you can get enough protection from lawsuits and you can get enough partnerships to have a little bit of a shield, that gets you another year closer to your eventual autonomous future.”
The subject of Google came up again when a news executive suggested that OpenAI’s next steps would reveal the company’s motives for ramping up news partnerships. Declaring that the Google News Initiative “in many ways is a PR initiative and still is,” they said, “part of my thinking about the OpenAI deals is they may very well also be just about PR. If they only do deals with a few select premium brands and they never talk to anybody else, then we know they’re really only interested in a few select premium brands and what they can do for their [own] brand.”
This point about opaque individual agreements touches on other topics that recurred in our conversations about licensing deals:
- the discrepancy between the selective nature of individualized agreements and the indiscriminate scraping that went into training the models;
- transparency around how AI companies choose media partners;
- the departure from traditional licensing agreements;
- the sustainability of individual deals.
An executive from a global outlet that had struck licensing deals understood that their outlet was part of a privileged minority. “How can Google pay for everything?” they asked. “It puts them in a slightly invidious situation because if they are to start choosing what news they’re going to license, it puts them in a kind of editorial position of choosing that news source, but not that one. And that’s tricky. But I don’t feel for them that much, to be honest, because it’s a situation of their own making, and they have to now deal with the consequences.”
This, of course, speaks to the longstanding charge that platform companies pick winners. One former platform executive said their team actively sought to counter this accusation. “You try to establish these parameters explicitly to counter the argument that you’re just picking winners. Most people … don’t want to hear it,” they said. Having given an overview of the inclusion criteria and valuation model their company used to calculate different news organizations’ compensation for participating in a global program (e.g. newsroom headcount as “a proxy for much it costs for them to run their business”; Comscore data as a measure of the size of their digital footprint; a definition of what constitutes a news publisher; minimum output requirements), they said, “We knew that [payment details] would be leaked to regulators. So we wanted to at least have the ability to say, ‘Well, look, you could say we were picking winners, but actually we were building a product according to the following criteria. We weren’t paying willy-nilly. We actually had a very specific calculation that we made for each publisher based on the following criteria applied to everyone.’”
Moreover, a number of interviewees implored news organizations to band together for the greater good. A former platform executive argued that generative AI upended the status quo to such a degree that existing precedents around licensing did not translate. “Generative AI is fundamentally different from one-to-one licensing elements,” they said. “So you may need much more collective ecosystem relations. … Whether it’s a tax or a profit share that goes into a pool that goes wider, there are approaches like that on a collaborative thing. But these one-to-one, confidential deals are not good for the overall ecosystem.”
Similarly, an AI strategist at an organization with a licensing deal expressed skepticism about the sustainability of the current deals, arguing that there is a shrinking window of opportunity as legal and regulatory pressure ramps up. “Calling [the deal] a partnership is a stretch. It is a licensing deal,” they said. “They paid us money for our archives. I think newsrooms need to get the money when they can, because I don’t think it’s going to be an endless source of money.” An AI leader at a global news organization agreed. “I suspect we’re at the high-water mark of it,” they said. “I suspect if you haven’t done a deal or aren’t doing a deal in the next six to 12 months, it’s unlikely to happen.”
Licensing deals and revenue shares are not the only ways in which AI companies have formed partnerships with news and journalism-adjacent organizations. OpenAI has partnered with WAN-IFRA to launch a newsroom accelerator program and given multimillion-dollar grants to the Lenfest Institute and American Journalism Project, and both Google and Microsoft have collaborated with news organizations to fund AI training programs. Here, too, some interviewees argued that market conditions meant some journalism entities had few options but to take payments from AI companies.
“There’s a healthy amount of skepticism about taking money again,” a board member of a nonprofit industry group admitted. “But I think from the nonprofit space, there’s not much else you can do, right? Where are the other sources of money that are going to cover [journalism]? … So I think for [nonprofit group], it’s also an existential matter. If we’re not a leader in AI in some way through technology money, then we’re a much smaller organization, a much different organization, I would argue. Not necessarily all the people on the boards would agree, but I’m of the mind that [nonprofit group] may not exist in five or 10 years if you don’t play in the AI space now.”
While headline figures guided most discussion of the financial aspects of existing deals between AI companies and publishers, some pointed out that details relating to mission, strategy, and allocation of resources shouldn’t be ignored.
The CEO of a nonprofit news outlet said their main rationale for signing a revenue-sharing deal with an AI company was to maintain visibility if audience habits shift: “Do you want to make sure that your news appears at all if generative search is the new way that people get news?” Unpacking their newly minted partnership, this CEO arrived at a modern variation on the mindset that underpinned much of the social era: That their news organization has to be nimble enough to adapt and meet audiences where they are. “No one here is doing this for any money. So that’s really where we depart from these big commercial companies,” they said. “As much as I personally am pessimistic [about generative AI] — it’s probably because of my background in media — I think we as [news organization] want people to find us however they can find us.”
Interviewees also stressed the importance of considering the additional labor attached to platform deals, noting that the return on investment can quickly evaporate if the demands present too large a departure from the organization’s own strategic road map. One executive recalled Facebook Live, the live-streaming video platform for which Meta paid a host of launch partners in 2016, when describing how they determine the appeal of licensing deals. “If we’re creating different content or experiences for these deals, is that furthering our business, or just theirs?” they asked. “The tools themselves are the product. Facebook Live was exciting for publishers because [Facebook] were paying us to create video. We ultimately decided to pull out because it was a bunch of shitty video for Facebook platforms that could not go anywhere else, and so ultimately you’re running in place. So similarly here, are there content experiences or product experiences that are beneficial to you beyond this deal?”
An AI leader from a large legacy brand raised a similar point. “I actually think it’s fine if we change what we produce based on the way that the information landscape changes due to AI. But we should do it because the landscape is changing, not because somebody’s paying us money to change. … I don’t think it’s that we shouldn’t change; it’s that we shouldn’t change because they ask us to change. We should change because our users demand something different from us.”
Finally, some interviewees expressed concern that the current wave of publisher-AI deals are primed to reinforce or exacerbate existing structural inequalities in the news industry.
For example, echoing the earlier discussion about different ways of conceptualizing the value of journalism, a person from an outlet that has a licensing deal argued that some small outlets would be overlooked because AI companies would not recognize what they can bring to the communities they serve: “I do worry about the smaller players. If you’re a newspaper in Paducah, Kentucky, for example, and you’re the only one in a four-county area, your content is really valuable because if somebody queries a question about that part of the world, they’re the only game in town. They’re the ones that the content that gets served up comes from. And they’re unlikely to see any money from that because they don’t have Sam Altman’s email address.”
The CEO of a local nonprofit — who had earlier lamented, “I have seen throughout my entire career disruptive technology that merely gives more wealth and power to those who already had an advantage in wealth and power” — said, “When the final deal is signed, the lion’s share of that money is going to have gone to the incumbents and it’s not going to go to small digital local publishers. That’s a second-order risk that this money is going to flow to The Atlantic and Axel Springer and whomever. It’s going to shore up incumbents in a way that in the long term perhaps disadvantages local or niche digital publishers who are five to 10 years old and therefore don’t have a corpus that lends itself to LLM training.”
Looking Ahead: Hopes and Fears
In keeping with the broad overall theme of uncertainty, we heard contrasting views about whether decision-makers’ experiences of earlier chapters in the platform-publisher relationship would increase or decrease the likelihood of forging a better future in the AI era.
Expressing concern that rapid turnover made the news industry vulnerable to repeating missteps from the past, one executive said, “There has been a shattering of a lot of the institutional memory. … A lot of the people who had been in charge or had learned from those experiences are now no longer there and so that brain drain has its impact.” Articulating how they sought to apply learnings from earlier missteps, they continued, “There’s a pervasive sense within news organizations that to be innovative is to run full tilt toward the next thing with reckless abandon, and my approach after 25 years of doing this is to look carefully at each piece, and certainly to learn and to experiment, but to be more careful, particularly given the experience I had over the past decade about how much we trade away in order to get the shiny new thing.”
We also sometimes heard the counterperspective: that a changing of the guard would benefit the industry as it navigates the present era. For example, one executive editor said, “There’s a bit of a risk that all the people who did the digital transformation are stuck in [their thinking in] this area and actually we need the new, energetic set of people who are coming through and thinking about this in a different way. They’re some of the most interesting people, because otherwise there’s a risk that we’re just thinking about it in the same way as we have thought about every other engagement with a technology company, and after 15 to 20 years of experiencing business model failure, we’re coming at it from a place of extreme cynicism.”
The impact of market forces
One notable driver of anxiety about generative AI is concern that intense competition between AI companies is sparking — and will continue to spark — rash, ill-conceived reactions from incumbents that have implications for publishers but that will barely register with protagonists whose focus is squarely trained on their market share and stock prices.
A number of interviewees from both the journalism and tech industries emphasized that OpenAI and Perplexity’s disruption of the long-stagnant search market — and, more specifically, Google’s response to that disruption — had scope to impact news organizations and the information ecosystem more broadly.
Rounding off a largely positive point about Google’s “engineering teams and product teams [historically being] interested in trying to solve the complexities of news engineering problems,” a news executive from a global outlet with a long history of partnering with the search giant added, “That’s less true now than it has been.” Referencing the generative AI arms race sparked by the launch of ChatGPT in late 2022, they said, “Google [is] not very good at being disrupted. … They don’t have a great business or technology response to what OpenAI are doing. And I think it’s really hard for them to see how they can respond to that challenge without treading on some of the things which matter to news publishers. For example, taking everybody’s journalism and turning it into their own product.”
During a discussion about generative search, an AI leader from another major international legacy news organization said that “Google, left to their own devices, absolutely wouldn’t be going down” the path of generative search. Another platform executive concurred, saying, “Google has been sitting on this technology for years … [but was] too concerned, I think rightly, about … all of the red flags that people associate with OpenAI.” Echoing the sentiment of the publishers above, this interviewee outlined how Google’s response to this unexpected disruption could have adverse repercussions for journalism and the information ecosystem more broadly. “They’re in an innovator’s dilemma, and have now come closer to ‘launch first, beg forgiveness later,’” they said. “And I do think [Google] will be pushing the limits a little bit with publishers on this.”
Another former platform executive expressed concern that the newfound competition in the search ecosystem was causing more harm than good, saying, “If you look at the beginning, after ChatGPT launched, and you look at some of the very well-documented stumbles that Google made trying to catch up, that competition wasn’t good. That wasn’t competition from a user perspective — it was competition because the market freaked out and the share price dropped. [Google] shouldn’t be thinking quarter to quarter about share price. But guess what? In the last 18 months, almost everything that they’ve done has been about the share price.”
Different mindsets
As we noted in Chapter 3’s discussion of the value exchange, there are numerous ways in which contrasting mindsets and practice have contributed to the tense relationship between platforms and publishers. Interviewees who had moved between the two fields were able to provide particularly insightful perspectives in this regard, detailing how attitudes prevalent during their stints inside Big Tech companies were primed to widen the chasm unless work is done to bridge the gap. We also heard numerous examples of ways in which certain levels of distrust have already started to percolate.
Differences in the speed at which technology companies and news organizations do business have long been a source of tension. The “different speeds of decision-making and reaction still exist,” according to one former platform executive, who said this disparity, combined with a lack of open dialogue between the two sides, was one of the main things that “turned the publishers into an annoyance” for their company. Not only is this “still a problem,” according to this person (who said they have been “feeling like I’m in slow-mo” since returning to the publishing world), but it also underscores a bridge that needs to be built as we move into the AI era.
Another area identified as having scope to cause tension is contrasting attitudes toward scale and optimal applications of generative AI. An interviewee with over a decade of experience at a platform company articulated why they saw contrasting mindsets and objectives as a recipe for disharmony: “Something that any journalist who has worked in a platform has heard over and over again from engineers is: ‘Well, that doesn’t scale.’ This is constantly what technology companies think of. Take the idea of giving tools to local news organizations that allow them to have two reporters on staff instead of five; from an engineering perspective, this is helping you scale. But that’s not how news organizations that are mission-driven think about scale. They think: ‘We have five reporters and our scale is that we are positively influencing or impacting the lives of all 140,000 people in our circulation area.’ That’s scale to them. But to a platform or technology company scale is: How much can you maximally do with the minimal amount of full-time staff? And it’s just a different definition and a different concept.”
During an impassioned argument about the need to address the broader structural issues perpetuating the journalism crisis, the CEO of a nonprofit local news outlet pinpointed another group to whom the above conceptualization of scale would hold great appeal: hedge fund groups that have made themselves villains of the local news crisis by taking over cash-strapped legacy news outlets and implementing savage cost-cutting.
“I want to be clear, I’m not saying ‘Stop AI. I’m going to stand athwart progress and say stop it.’ I’m not saying that at all,” this CEO said. “The problem right now in journalism is that massive things are not getting covered. … [I]n the absence of original reporting, any degree of further technological interposition is not going to do that much. … [Generative AI] could make more efficient the stuff that is more functional. But for that functional thing to keep functioning, we need jobs and we need opportunities for people to gather news. And so simply applying AI, if that functional part of journalism has already been so severely reduced, is not ipso facto going to help.”
Riffing on a hypothetical example of generative AI enabling an under-resourced education reporter to synthesize and follow up on transcripts from a large volume of education board meetings, the CEO said, “So yes, it will help journalists become more efficient. But I also worry that Alden [Global Capital] will be like, ‘Okay, well, we’re definitely reassured now that one reporter can cover the 12 school districts.’ So it cuts both ways.”
Early signs of distrust
Even in this relatively early period in the AI era, numerous interviewees articulated ways in which distrust of AI companies has started seeping in.
For example, an AI leader at a global news organization had already encountered vastly different levels of transparency and candidness about unauthorized scraping from one AI company to the next. “Some [AI companies] will admit, ‘Yes, your content has been used to train our models, but we believe [it is] fair use, we’re absolutely covered, we’re going to have to agree to disagree,’” they said. “But others you can’t even draw a conversation and at least one organization has told me to my face, literally, ‘I have just checked our data and there’s none of your content in there, don’t worry.’ Which is clearly a complete lie.”
Another AI leader at an international local news chain expressed a sense of betrayal about having been sounded out to share expertise on an upcoming generative AI product, only to be shunned once it was released. “I spoke to [AI company] about this [last year] and they promised that we would have access to have a look at it,” they said. “Then when it came out, it’s all, ‘NDA. We’re not going to speak to you about it.’ … Essentially, they’re just looking to see what more they can automate and what more they can take off of us.”
Distrust also bubbled up in regard to AI companies’ claims about the scope for news summarization products to keep driving meaningful traffic. No doubt conscious of some news organizations’ historical reliance on search — “the superhighway for almost every news organization’s traffic,” as one executive put it — AI companies have been at pains to reassure publishers that their news summarization products are being designed with an eye toward aiding journalism and providing publishers with an ongoing source of meaningful traffic.
For example, OpenAI’s July 2024 press release announcing SearchGPT stated, “For decades, search has been a foundational way for publishers and creators to reach users. Now, we’re using AI to enhance this experience by highlighting high quality content in a conversational interface with multiple opportunities for users to engage. SearchGPT is designed to help users connect with publishers by prominently citing and linking to them in searches. Responses have clear, in-line, named attribution and links so users know where information is coming from and can quickly engage with even more results in a sidebar with source links.”
While an executive at a global outlet who has engaged with OpenAI over its handling of news spoke positively about the company’s willingness to respect their feedback on the appearance of their journalism and the implications for traffic — “They have definitely taken on board the comments that we made in the early round” — other interviewees harbored doubts.
For example, an AI leader from a major legacy outlet expressed deep skepticism that claims about careful user experience design considerations and the like would translate into meaningful traffic. “The fact that we’re, at this point, largely dependent on external actors for large portions of our traffic as an industry [is a concern]. I don’t think there’s a single person out there that believes any of this like, ‘Oh, they’ll be links and they’ll be in color and … ’ No one clicks links. We know that. It’s just not happening,” they said.
Some publishers were wary that history could repeat itself if AI companies become more aggressive in their efforts to keep audiences within their walled gardens. For example, an executive from a global outlet with a licensing deal noted, “You’re relying a little bit there on OpenAI being happy to drive traffic out. And you wouldn’t have to wind the clock too far forward for them to come up with something like [Facebook’s] Instant Articles: ‘We’ve got an even better idea [than driving traffic to publishers]. We can drive traffic, but let’s not drive it out. We’ll just have it driven internally. We’ll have the whole verbatim article.’”
Cross-pollinating expertise
One possible way to help bridge this divide, raised by interviewees from both camps, is to ramp up the cross-pollination of expertise, installing more people who understand the mindset and language of tech in news organizations, and more people who understand the mindset and language of journalism in technology companies.
A news product expert argued that a strong grasp of technology is now as critical to news leaders as an understanding of business and journalism. “News organizations are digital businesses now. You need to have people who care about the mission, the community, the ethics, the journalism, who understand that news is not a great business to be in because it’s expensive to produce journalism,” they said. “All those economic complications mean that if you don’t understand and care about the mission of journalism, you’re going to have a very hard time running the business. On the other hand, if you don’t understand how technology works and how that implicates itself in the monetization, the collection, the distribution, the operation of news, you can’t run the organization very effectively.”
“If the CEO’s not a technologist — and they don’t need to be, but it wouldn’t hurt — you need to have a chief product officer, or a chief technology officer, or somebody like that who’s in the boardroom making the arguments from a mature, critical perspective,” they added.
The CEO of a local nonprofit — who would not describe themself as a technologist — independently raised the need to give staff with technological expertise a seat at the top table when it comes to AI. “You need journalism leadership involved in this, but you also need product leadership more than ever right now. I believe that the technologists, product managers, the engineers, especially the data people, and audience, should be among those leading the conversation,” they said.
Interviewees from the platform camp — who, it should be noted, all came from journalism backgrounds themselves — also suggested that relations could be improved if even more staff with news expertise were integrated into technology companies.
Some referred to earlier periods, when their respective employers bulked up their journalism head counts, recalling their potential for relative harmony. “The thing that characterized [platform] at that time was there was a large group of people who came from journalism and whose job it was to understand journalists and to understand how central that was to us,” said one. “So our relationship [with publishers] was much more symbiotic. We were aware of the centrality of news, so we behaved differently [from Facebook to] find ways for publishers to work with a platform and actually have genuine ways to kind of make money.”
An interviewee from another platform argued that a drive to recruit staff with journalism expertise had coincided with what they saw as a brief period of cohesion. “This whole idea of having people fully empowered on staff at a tech company who understood journalism [and had] authority and controls that they could employ started around 2014, 2015,” they said. “I think that mirrors this optimism in the media at the time of like, ‘Oh, we can work with the platforms. We can talk to Twitter’s curation team. We can talk to Apple News’s curation team. We can talk to this team at Google who works on Newsstand. We can work with people who speak our language and there can be a mutually beneficial relationship.’” They noted, however, that this era had been short-lived. “That lasted through November 2016 to January 2017. The election of 2016, to put it mildly, was a total sea change in how platforms thought of content in their products.”
A former executive from a third platform said cross-pollination “would be an incredibly smart thing to do.” But, they added, “I just see the opposite happening at the moment. Like, Meta has pretty much let everyone go who was an expert in journalism. … You need people from both sides going to the other and educating and building up the trust, so that this grown-up conversation can happen. We were actually half there, then this setback came. But I’m optimistic enough that in a couple of years’ time, they will say, ‘Okay, we cannot run away from this. We need to figure out another solution. We need people who can talk to each other, who understand the language and understand the different positions.’”
While nobody dismissed this idea out of hand, a fourth former platform executive was cooler on the notion of cross-pollination as a benefit to both industries. “More tech-minded folks within news for sure,” they said, noting that there’s “a broader discussion about where real engineering talent wants to go. … The BBC is not going to pay the way that Meta can pay. So that talent war is a bit lopsided in many ways.” In relation to their former employer, they said, “We’ve been making that investment [in journalism] for many years. … It’s been defunded in a lot of ways. But it’s still there and there’s still large budgets associated with it, so there are a lot of ex-journalists in the house at [platform], no question.”
Challenges to news discovery and new outlets
Discussions about generative AI products and platforms led some interviewees to outline how expected developments could have implications far beyond any one organization, tool, or business deal.
Multiple interviewees argued that the current trajectory, as they saw it, pointed to a future with intimidatingly high barriers for those seeking to enter the news market. “We’re at the mercy of the platforms,” an AI strategist said. Platforms “are in control of everything at this point. And they’re even going to control how people see information. What can newsrooms do to build a defense? They can have newsletters, they can have podcasts, they can develop their own apps. But that’s [only] if you have name recognition right now.”
An audience executive agreed that diminishing opportunities to reach audiences through platforms, combined with a rise in generative news summarization platforms, posed a serious threat to news discovery: “If you believe that social is zero and search is zero, then what are you left with? Genuinely, where do people find out about news? How are you even aware as a news consumer of any brand, any [journalist]? Is it just all TikTok creators? That, I think, is the central question that nobody has answered. If you really, truly believe in that future, then it’s fine if you’re an existing player because you can draft off your existing user base, but you cannot start something new without an awareness play. And that’s really going to suck because we really believe in the new news brand. The industry needs this bloodstream of new players that come in. If you’re going to start The Verge today, you don’t start a website, right? You’d be crazy to start a website. You can do a 404 Media because those people came from the web, and so you would follow 404 people from web to web. But if you start something brand new, with no known people, and just a lot of energy and a few dollars to your name, how do you start that organization? You just don’t, you can’t do it. And so you start as a creator, but that’s a slightly different point of view.”
Elsewhere, several interviewees pointed to a plethora of ways in which decisions made in Silicon Valley could have far-reaching implications that require careful attention and action now. Building on a point about media plurality, an executive of a global news outlet said, “The idea of [generative] AI being a single source of truth is profoundly disruptive. It’s disruptive to commercial models, it’s disruptive in terms of democracy and choice of media sources. … One of the most profound short-term issues is if Google becomes primarily driven by single-answer search — and there are good, interesting questions about whether the consumer would accept it, because the search norms are so established — but the risks of bias, the risks of disinformation, the risk of monopoly, all become much, much greater.”
An executive from another global news brand outlined the broader case for figuring out an acceptable value exchange between AI companies and news publishers, which extends far beyond any one agreement or check: “The line we’ve been taking with regulators is that there’s actually a really significant societal dimension to this. Because if we do all fail to strike licenses and we do all say, ‘No, you can’t take our journalism anymore,’ and [meanwhile] there is this behavioral shift that means people are increasingly relying on those tools … if you begin to limit the information that’s going into these machines, pretty soon they’re not going to be machines that [audiences] can trust.”
Collaboration among publishers
Faced with the litany of potential and, in many cases, actual challenges discussed in this report, many interviewees’ attention turned to how publishers can navigate the expected upheaval. One recurring theme centered on a perceived need for greater collaboration among news publishers, and Europe was often held up as the brightest hope for where such collaboration might take place.
The notion of journalism outlets working together came up in a number of contexts, such as:
- Larger, better-resourced organizations sharing with smaller ones;
- Knowledge sharing between news organizations to help peers tackle issues created by emerging platforms and technology;
- Collective bargaining over licensing deals (where allowed);
- Negotiating as a bloc over demands for data.
At the simplest level, interviewees expressed hope that larger, better-resourced news organizations would share knowledge with peers that have less capacity to experiment with AI technology. Pointing to instances in which newsrooms have collaborated on high-profile projects, an interviewee with deep experience in both fields said, “We need to apply the same principles of collaboration and openness as we move into this AI era because we all have to support each other to make sure that the industry as a whole is sustainable.”
Outlining how that could materialize, not just when it comes to blockbuster projects, but in more mundane situations, they said, “It would bring me great joy to hear that engineers or developers were in touch with each other, their product managers sharing tidbits and nuggets of information. I want to see more of that across different types of news organizations. The larger legacy organizations should be sharing information with the nonprofit, independent newsrooms who have much fewer resources and really small teams that could benefit from that knowledge.”
Though this was not a subject about which interviewees were explicitly questioned, we heard occasional responses that suggest there is already enthusiasm for this kind of knowledge sharing. For example, a machine-learning engineer from a large legacy outlet said, “[The reason I am] so interested to be in this field is to help ideally steer it in some direction that will be helpful. Being able to utilize some of the resources of [news organization] to give back to smaller newsrooms by either establishing principles, or lessons, or things that can be shared, or developing open source software or other tooling that can be helpful for journalists or knowledge professionals outside of journalism, too.”
Other interviewees advocated for knowledge sharing among peers to negotiate the expected upheaval resulting from rapid advancements in generative AI technology, and the (potentially premature) rollout of platforms and products expected to disrupt the information ecosystem. “You have to be very vocal and be insistent about your expectations as a distributor within these platforms,” said one executive editor at a major international outlet. “You have to share your thoughts and talk an awful lot within the industry and understand how other organizations are approaching the same challenge.”
Elsewhere, interviewees encouraged collaboration as a means for fighting larger, albeit less specific, existential threats. For example, one AI strategist said, “If model collapse doesn’t happen, and they’re able to train these models on created text or images, if they’re able to do that without model collapse, then they’re going to do it. And we will be useless [to the AI companies] once again. I worry that we are slow to act, that we often act independently and not together as an industry, that we have a failure of imagination as to what could happen next. And we’ve seen a lot of this happen again and again and again, where the platforms come in, they on the face say that they’re very interested in news and give us this whole song and dance, and then all of their actions speak to the opposite of that.” An AI leader at an international local news chain agreed: “Publishers just need to unite on it. As a bloc, we’re far more powerful than individual people making different deals with shady tech companies that we’ve already been scalded by before and are just doing the exact same divide and conquer again.”
Overall, while there was an encouraging level of enthusiasm for collaboration, it was tempered by regretful admissions that interviewees didn’t necessarily expect to see it come to fruition.
The AI leader from the local chain conceded, “You just see it happening again. We need to work together to do it. But I actually don’t think that’s going to happen.” (emphasis ours)
Similarly, an executive at a large legacy news brand suggested that talk about collaboration isn’t always matched by action. “We have trade associations, and we talk about all this stuff, and there’s plenty of collaborative,” the person began, then paused before continuing. “There’s plenty of talk about how to handle this stuff, but there’s not a lot of collaborative—” They paused again, then admitted, “I stopped on that because it actually doesn’t feel quite right. There may not be enough collaborative work among publishers to figure out how to fight this thing together, and there should probably be more of that.”
This need for improvement was echoed by a former platform executive who urged publishers to shed traditional rivalries for the good of each other and the information ecosystem at large. “In this shift to the era of generative AI, I believe you have bigger problems and issues than your local competitor. You’re seeing structural overall shifts happening. But if you take the attitude that you took before, I don’t think it’s going to serve you well in this era,” they warned. Indeed, over the past year several editorial unions have successfully bargained for protections against job displacement by generative AI tools.
Platform-publisher collaboration
A handful of interviewees spoke enthusiastically about the prospect of AI companies and publishers developing ways to collaborate and derive mutual benefit from generative AI, rather than simply coexist in separate silos. The CEO of a large global legacy newspaper brand said, “There are some tech businesses and organizations that are emerging, either big or very small, that do actually want to participate and see their futures being based on a set of partnerships and greater collaboration.”
This is not entirely without precedent. One former platform executive described a period where their company and a group of news organizations “developed an agenda together” as the “halcyon days” of “peak collaboration.”
Reflecting on their experience of the platform-publisher relationship and thinking about learnings to bring into the era of AI, a former executive of a large international news organization said, “The major lesson, and I may sound naive, is that there was room for collaboration. I say that very explicitly because I’ve said it openly in public as well, that tech platforms and the media industry, of course, could work together. And there was a space for innovation that we couldn’t have achieved without the help and the vision of tech platforms.”
An executive at a large international news organization noted that the way in which platforms approach such collaborations matters: “If [a technology company] comes to us and says, ‘What’s a problem that you need solving?’ and then they come back with a response, that’s always quite encouraging. If they say, ‘We think we know what problem you’ve got, and so we built this, do you like it?’ that’s generally less encouraging.”
Some interviewees advocating platform-publisher collaboration expressed hope that formal arrangements could be agreed as part of licensing deals. For example, the former news executive argued that contemporaries in their former role should “not only focus on the money” but lean into their different skill sets and pursue a “combination in terms of giving me some money and [exploring] how you can help me to scale up my operation.” To achieve this, they said, they would seek answers to the question, “How can your teams and my teams work together to produce services [and] produce different layers of products that are different from those that already exist and that can make a significant impact on my audience?”
Much like the relatively small band of individual licensing deals struck since 2023, this sort of formalized collaboration is not necessarily primed to scale. (Although it should be noted that people that have participated in or led accelerator programs and other training have typically spoken favorably about the experience.) Even then, though, while some interviewees from outlets with licensing deals have been encouraged by the early signs, others suggested opportunities to forge more collaborative relationships are again being overlooked.
For example, an executive who has been privy to negotiations around licensing deals argued that unknowns about the future direction of the technology meant agreements should have a “dynamic element” that facilitates “a partnership in its truest sense” rather than a “one-stop shop.” “In an ideal world, the constant stream of content that is produced every day will have a contribution to [an AI company’s] model, and that needs to be reflected in a partnership,” they said. “Having a mutual benefit out of the license is good. But what I see today is primarily publishers trying to get their hands on as much money as possible now without a lot of thinking through, ‘Well, what is this going to look like in five years’ time?’”
The executive noted that the short-term pursuit of hard cash may distract from longer-term issues, including some of the more existential questions. “Is there a way [AI companies] can say, ‘Thank you, that’s enough. We don’t need any more [of your journalism]. We’re done. We can now generate our own and simulate you enough so that we don’t require your license any longer’?” they wondered. Part of what needs to be addressed is “How can I become an essential part of their business, and how do they benefit from having access to my business?” the executive said, adding: “I have not seen a single contract that reflects that today. The contracts today are, ‘Here’s a pile of money. Shut up. Give me access to your content. But primarily shut up.’”
Conclusion
Although much of the discussion we had with news executives, editors, current and former platform executives, and AI experts in summer 2024 was shrouded in uncertainty, the unknown casting a shadow over every aspect of the current landscape is the high-stakes fight over copyright and intellectual property rights.
It is clear from the wide array of internal experimentation taking place that newsrooms see considerable potential in generative AI. But for most of our interviewees, it was just that: potential. Almost all said they were extremely cautious about moving any of those experiments into production given their concerns about the limitations of the technology and its potential to damage brand integrity and audience trust.
Given this hypervigilance around using generative AI on platforms they can control, it seems entirely reasonable that interviewees expressed unease about the ways their brands and content get remixed and presented on third-party platforms they do not control. That much of the underlying data was taken without notice, permission, or compensation only adds to the discontent.
The generative AI arms race has created a cutthroat market with eye-watering amounts of money on the line. In 2023, Bloomberg Intelligence estimated that generative AI could become a $1.3 trillion market by 2032. In addition to the other threats they face, news leaders fear that their organizations will become collateral damage in this high-stakes war.
For news organizations, there are a lot of wait and sees:
- Wait and see what AI companies have in store for generative AI, the extent to which the technology lives up to its transformative promise, and how long that maturation takes.
- Wait and see what value proposition AI companies put in front of publishers whose intellectual property they need to power their LLMs.
- Wait and see how the high-stakes copyright cases moving through the courts will be resolved, and the implications of the eventual rulings.
- Wait and see how much appetite governments have to intervene regarding copyright and/or the survival of journalism, for good or ill, and what form those interventions take.
- Wait and see how quickly Google reforms its search platform to prioritize AI summaries.
- Wait and see how quickly audiences’ deep-seated expectations and habits around search shift in response to changes to search infrastructure.
- Wait and see to what extent new or existing players establish a foothold in search and other fields that intersect with journalism.
- Wait and see what impact those changes to the information ecosystem have on publishers’ businesses.
The list goes on. But the common thread is that these are situations over which most publishers have minimal, if any, control – and whose outcomes could transform or destroy journalism as we know it.
This litany of unknowns is, of course, why so many interviewees stressed that direct relationships with their audiences — already the lifeblood of most viable business models — have taken on even greater importance: Cultivating and strengthening those audience relationships is one variable they can control.
Traumatized publishers can be forgiven for having little appetite for renewing their vows with platforms – the proverbial fickle ex with a track record of abandoning their half-hearted attempt at couples’ therapy at the first sign of trouble; perhaps they can also be forgiven for forming new relationships with less familiar partners who share many of their ex’s most problematic traits, including a propensity for making public pronouncements of love and commitment during the courtship stage, while insisting that they are different.
Upheaval is nothing new for publishers and, as many of our interviewees made clear, it is not the prospect of upheaval that is causing consternation, per se. Rather, it is the prospect of reliving the existential dread that characterized previous periods when the actions of highly competitive technology companies disrupted aspects of the information ecosystem on which news organizations depend.
The purpose of this report was to analyze the state of the relationship between platforms and publishers, an assessment we have conducted periodically over the past decade. While our interviews surfaced many familiar tensions — such as frustrations over a lack of shared understanding of what constitutes a fair value exchange and concerns about how intermediaries surface and credit original reporting — this latest round of conversations shed light on an urgent development: the abstraction of journalistic content away from its creators.
Journalism is far more than the act of gathering data. Yet the companies driving the development of chatbots and generative search tools — technologies that may soon become the primary gateways to news — show little interest in recognizing, valuing, or providing adequate transparency to the news production process. This separation of news content from its sources, combined with the continuing decline in search traffic and social media referrals, threatens to usher in a moment of Journalism Zero — a point at which the ties between journalism and its audiences are completely severed, leading to untold consequences for both the news industry and the health of the information ecosystem.
This report has hinted at implications for news organizations. For example, some interviewees had firsthand experience of Google becoming less attentive to long-term partners, a concerning development that lines up with former employees’ concerns that, facing unexpected disruption in the search space, the company “will be pushing the limits a little bit with publishers.” As the biggest incumbent, one can only hope the company heeds the call from a former platform executive who said, “I would like to remind Google that they are an ecosystem company.”
Trust is commonly discussed in the context of audience trust in the news media, individual news organizations, and technology companies, but there are also trust issues to be resolved and/or established between platforms and publishers. As a former news executive at an international outlet with deep experience negotiating with technology companies noted, “This doesn’t apply specifically to generative AI, but a general criteria that applies to every single partner you sign an agreement with is that you need to trust that partner and you need to feel sure that partnership is not going to impact you in a negative way.”
Even the former platform executive who expressed most optimism that platforms and publishers will not just rekindle their relationship, but improve it, admitted to being “a little bit afraid that the platforms want to try their old game, and their old tricks,” which they described as, “Do something and ask for forgiveness later on.”
We are also waiting for other incumbents to show their hand.
One CEO at a global outlet said, “The unknown for me is where Apple participates in this. Google’s role is quite clear. Facebook’s role is really clear. OpenAI and Perplexity and Anthropic all get a map on a kind of spectrum to some extent. But [regarding] the future of Apple and Apple’s place with news and news partnerships, I have much less of a sense of where they’re going to end up in this overall ecosystem.”3While no interviewees expected Meta to pivot back to journalism from creators, one noted that Meta’s retreat from news likely occurred just as news content was among the inputs for the company’s LLM, Llama. “They probably use news in products like Llama, so they will use news as an input to their future product set in a way that they potentially haven’t done for many years. So the relationships ended at a time when the value of news to them has probably increased, which is a vicious irony.” On October 25, 2024, after our interviews had concluded, Axios reported that Meta had struck a multiyear deal with Reuters to provide real-time data for its AI chatbot.
One thing that’s certain is that publishers have a wealth of experience to draw upon when it comes to dealing with technology companies. News organizations have been developing direct relationships with platform and search companies since the early 2000s. But while some of this longitudinal knowledge has informed publishers’ perspectives and enabled them to react more quickly to change, it may ultimately be showing news organizations the nature of their own oppression without helping them secure a future for their industry.
Indeed, revisiting earlier iterations of this study, it is difficult to escape a feeling of déjà vu.
Concluding our 2018 report, we reflected on the challenges publishers faced securing meaningful audience data; the unexpectedly high technical debt of servicing platform innovations and their underwhelming financial returns; the exacerbation of structural inequalities in the news industry by platform actions that delivered disproportionate benefit to the biggest incumbents; and the realization among publishers that direct relationships with their most loyal audiences needed to be prioritized over the vast drive-by audience delivered during the sugar rush of the traffic era (before the audience taps were abruptly turned off). We also noted that there “remains the challenging question of whether or how to draw regulation which positively supports reporting organizations while curtailing the concentrated power of technology platforms.”
The extent to which publishers draw upon that experience in the AI era and avoid mistakes of the past remains to be seen. We heard optimism that lessons have been learned, and concern that mistakes will be repeated.
The playing field, rules, and referees are different this time, too. In the AI era, external forces such as legislators, regulators, and the courts will play a greater role in implicitly or explicitly shaping the terms on which decision-makers in the upper echelons of AI companies and news organizations renegotiate their coexistence in a reconfigured information ecosystem.
The stakes are arguably higher than ever. The concentration of information control among a few private corporations risks undermining journalism’s ability to be the watchdog in a healthy and informed democracy. Along with concerns about media plurality, bias, disinformation, and threats to commercial modes, interviewees identified significant hurdles for new entrants into the news market.
Many believe that publishers’ worst strategy would be to try to go it alone. Time and again, our interviewees pointed to the need for collaboration as the key to navigating the next period of upheaval. This included calls for rare, but not unprecedented, collaboration between rival publishers, international collaboration, and direct collaboration between publishers and AI companies.
Interviewees are divided on how this will ultimately shake out. Surprisingly, some of the most optimistic outlooks came from interviewees on the news side. “More and more, I think nothing is inevitable about this one-sided relationship,” a policy executive at a global outlet told us. “I think publishers shouldn’t lose hope that they don’t have the tools and the ability to stop all of their content being taken and used without consent. They should have confidence that if they produce great journalism it still has incredible value in the context of these new technologies. It’s just a question of: How do we establish the right frameworks to recognize that value and ensure that those revenues should be flowing back into creating more great journalism?”
In a similar vein, an experienced news executive urged peers to hold steady through periods of upheaval: “We have stayed really firm and strategic to our principles even in the hardest and scariest moments, and I think more publishers have the space to do that than they think.”
Despite the newness of generative AI, interviewees already had an eye on the future. Some talked about the role news will play when agent-to-agent use cases gather momentum. One identified quantum computing as the “element that drives everyone crazy and will probably reset the whole debate.”
If nothing else, this could spell good news for researchers.
“I don’t think you should finish off your series,” they told us. “You’ll probably have another one when supercomputing comes into the picture.”
This report began with an experienced news executive describing their many years of interacting with technology companies as a “long, strange trip.”
It seems unlikely that trip will end anytime soon.
Acknowledgments: Aisvarya Chandrasekar, Emily Bell, Vanessa Gezari, Vicky Walker, Hana Joy
Has America ever needed a media defender more than now? Help us by joining CJR today.
Klaudia Jaźwińska is a journalist and researcher for the Tow Center who studies the relationship between the journalism and technology industries. Her previous affiliations include Princeton University’s Center for Information Technology Policy, the Berkman Klein Center’s Institute for Rebooting Social Media and the Our Data Bodies project. Klaudia is a Marshall Scholar, a FASPE Journalism Fellow, and a first-generation alumna of the London School of Economics, Cardiff University and Lehigh University.