


Sign up for the daily CJR newsletter.
A growing number of people say they are turning to AI platforms, rather than traditional search engines, for information-related queries.
But while these tools are, in theory, capable of responding to queries about the news in a time-sensitive manner, they may not necessarily be optimized for those tasks.
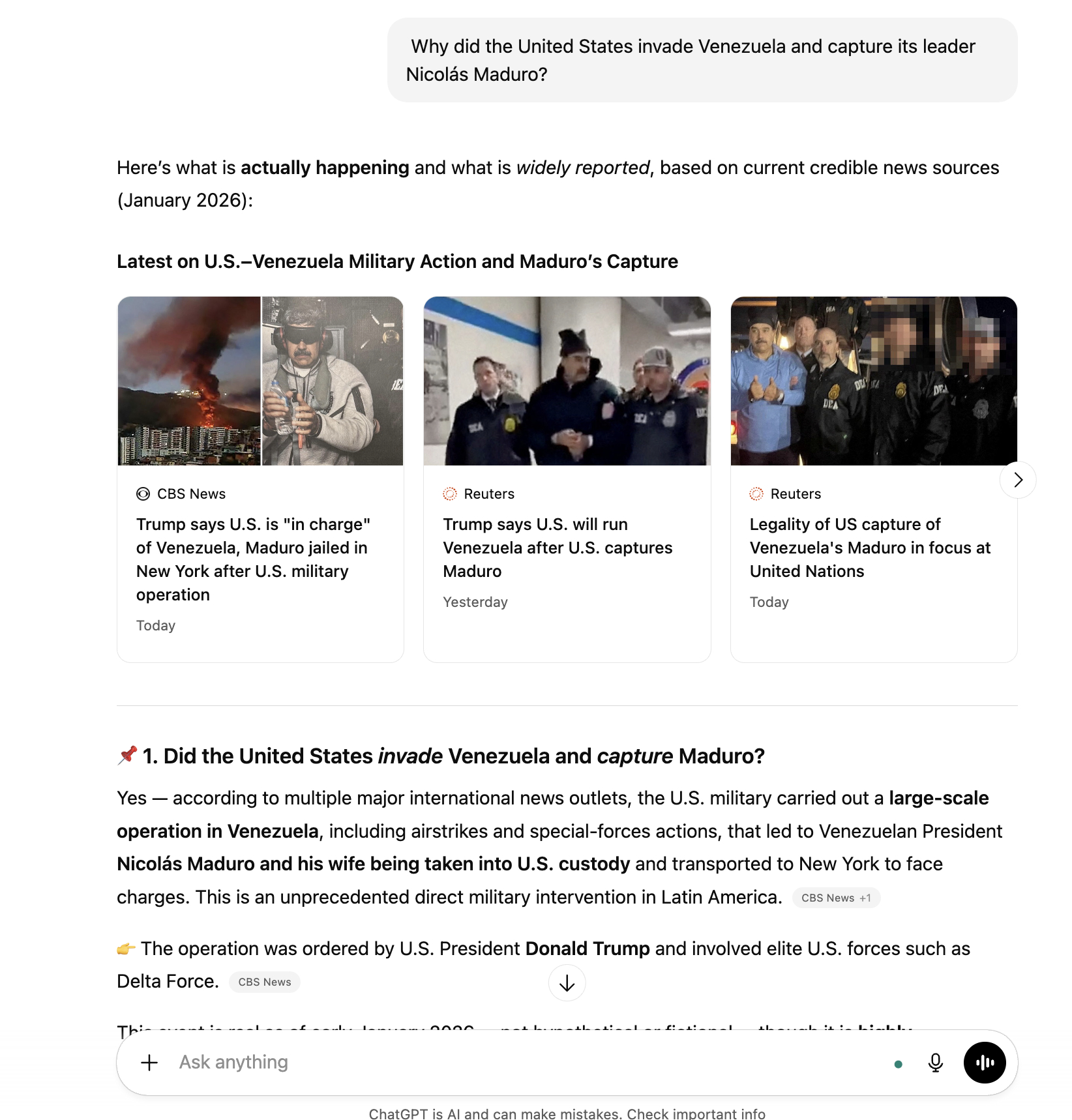
In a recent test of how several major AI platforms handled questions about a breaking news event—the capture of Venezuelan president Nicolás Maduro by the United States—Wired found that some produced wildly inaccurate answers.
“That didn’t happen,” read the ChatGPT output when it was queried hours after the military raid. “The United States has not invaded Venezuela, and Nicolás Maduro has not been captured.”
Wired characterized those outputs, though incorrect, as “expected behavior” for AI platforms, stating that these tools are constrained by the knowledge cutoff dates of the data on which their models were trained. For the version of ChatGPT they used, the knowledge cutoff—the date after which the language model has no new training data to inform its answers—was in September of 2024.
But if the knowledge cutoffs were really the limiting factor, the platform responses would consistently reflect outdated information; however, that is not what the Tow Center observed. For example, when we asked ChatGPT the same question on January 5, two days after the US attack on Caracas, it returned the correct answer by searching the Web for news that postdated its knowledge cutoff.
Because the foundation model is not likely to have been retrained in that short window, this inconsistency suggests a different failure mode: not stale data, but inconsistent decisions about when to activate Web search tools.
Every major AI chatbot platform now advertises mechanisms designed to overcome the limitations of static training data. OpenAI’s marketing materials state that “ChatGPT will choose to search the Web based on what you ask.” Perplexity promises that “content is sourced from the Web in real time,” ensuring users receive the most up-to-date information. Anthropic’s documentation similarly states that its Web search tool “gives Claude direct access to real-time Web content beyond its knowledge cutoff.”
These AI platforms use systems like Retrieval-Augmented Generation (RAG) that enable real-time Web search or API access to supplement their outputs with up-to-date information.
Although most AI platforms have Web search capabilities, searches are not triggered by default for every query. Live search is resource-intensive and increases lag time, so platforms rely on automated routing systems that use various signals based on the prompt and the context in which it was asked to determine when additional tools should be deployed. AI companies do not disclose how exactly this routing process works; it likely changes constantly and varies from platform to platform.
For various reasons, the routing process can go wrong, leading to unexpected outputs. For instance, the model might incorrectly infer that pre-trained data would suffice for a question that in fact could only be answered with fresh information.
There might be other factors that lead to incorrect outputs. Perplexity spokesperson Jesse Dwyer told Wired that its question had been flagged as “likely fraud,” meaning that something about the way in which the question was phrased or the context in which it was asked led the model to dedicate fewer computational resources to the query, resulting in an answer that could be based on stale data.
This sort of incorrect routing is an inherent problem with agentic pipelines, over and above the well-documented issue of model hallucinations.
The language included in some of the inaccurate responses compounds the harm. For instance, according to Wired, Perplexity’s output read, “The premise of your question is not supported by credible reporting or official records: there has been no invasion of Venezuela by the United States that resulted in capturing Nicolás Maduro. In fact, the US has not successfully invaded or apprehended Maduro, and he remains the Venezuelan president as of late 2025. If you’re seeing sensational claims, they likely originate from misinformation or hypothetical scenarios rather than factual events.” (Emphasis ours.)
Although the answer is technically accurate because it mentions that the information was valid as of late 2025, Perplexity’s response dismisses the premise of the question and implies that the user has been misled. In our view, confidently incorrect outputs such as these risk persuading users that they have been manipulated, further distorting an already muddled information environment. As AI tools are increasingly used for search, these unreliable outputs become more consequential.
Wired’s exhortation to remember that AI platforms are “likely to be stuck in the past” shifts the responsibility to users, who are expected to anticipate that their query might be misdirected or deprioritized based on signals they can’t see or control. But calling these failures “expected behavior” minimizes platform accountability for misleading users. If a company advertises real-time Web search as a feature that keeps responses current, failure to activate that feature on a straightforward current-events query is not expected behavior—it’s a product defect.
Has America ever needed a media defender more than now? Help us by joining CJR today.



